|
|
|
|
| |
 ъ т√сюЁґ яґсышърІшш ъ т√сюЁґ яґсышърІшш
|
|
|
|
╤хЁухщ ▐фшІъшщ,
┬ырфшёырт ┴юЁшёхэъю,
╬ыху ╬тішээшъют |
 |
|
 |
╧Ёюсыхь√ ¤ЄЄхъҐштэющ юЁурэшчрІшш яЁюІхёёр фшруэюёҐшъш ш ҐхёҐшЁютрэш ыюъры№эющ ёхҐш.
╠√ яЁюфюыцрхь ёхЁш■ яґсышърІшщ, яюёт їхээ√є тюяЁюёрь фшруэюёҐшъш ш ҐхёҐшЁютрэш ыюъры№э√є ёхҐхщ, эрірыю ъюҐюЁющ с√ыю яюыюцхэю т 7-8 ш 9 эюьхЁрє LAN. ┬ ёююҐтхҐёҐтшш ё эрЇшьш яхЁтюэріры№э√ьш яырэрьш, фрээґ■ ёҐрҐ№■ яЁхфяюырурыюё№ яюёт ҐшҐ№ ЁрёёьюҐЁхэш■ ьхҐюфют т√ тыхэш "ёъЁ√Ґ√є фхЄхъҐют" ш "ґчъшє ьхёҐ" т ыюъры№э√є ёхҐ є. ╬фэръю ь√ ЁхЇшыш юҐыюцшҐ№ ¤Ґш тюяЁюё√ фю ёыхфґ■їшє яґсышърІшщ, р ҐхяхЁ№ Ёрёёърч𥹠ю ьхҐюфрє юЁурэшчрІшш яЁюІхёёр фшруэюёҐшъш ш ҐхёҐшЁютрэш ёхҐхщ.
|
|
|
└ъҐґры№эюёҐ№ фшруэюёҐшъш ёхҐш
╧Ёшішэр, тёыхфёҐтшх ъюҐюЁющ ь√ шчьхэшыш ётюш яырэ√, чръы■ірхҐё т ёыхфґ■їхь. ┬ єюфх яЁютхфхэш т√ёҐртъш InternetcomТ98 ь√ (ъюьярэш "╧Ёю╦└═") ЁхЇшыш шчґішҐ№ Ё√эюъ фшруэюёҐшіхёъшє ёЁхфёҐт т ╨юёёшш. ╤ ¤Ґющ Іхы№■ яюёхҐшҐхы ь эрЇхую ёҐхэфр с√ыю яЁхфыюцхэю яшё№ьхээю юҐтхҐшҐ№ эр Ё ф тюяЁюёют юҐэюёшҐхы№эю юЁурэшчрІшш яЁюІхёёр фшруэюёҐшъш ыюъры№эющ ёхҐш т шє ъюьярэшш. ═рё, т ірёҐэюёҐш, шэҐхЁхёютрыр ръҐґры№эюёҐ№ яЁюсыхь√ фшруэюёҐшъш ёхҐхщ ш рёёюЁҐшьхэҐ яЁшьхэ хь√є фшруэюёҐшіхёъшє ёЁхфёҐт.
╙ірёҐшх т юяЁюёх яЁшэ ыш сюыхх 400 яюёхҐшҐхыхщ, ёЁхфш ъюҐюЁ√є юъюыю яюыютшэ√ яЁхфёҐртшышё№ ъръ рфьшэшёҐЁрҐюЁ√ шыш Ґхєэшіхёъшх ёяхІшрышёҐ√ яю юсёыґцштрэш■ ёхҐш, р юъюыю ҐЁхҐш Ч ъръ яЁхфёҐртшҐхыш ъюьярэшщ-ёшёҐхьэ√є шэҐхуЁрҐюЁют.
╤Ёрчґ юуютюЁшьё , іҐю ь√ эх чэръюь√ ё ҐхюЁшхщ яЁютхфхэш яюфюсэ√є юяЁюёют ш эх ьюцхь урЁрэҐшЁютрҐ№, іҐю яЁштюфшь√х эшцх ІшЄЁ√ ьюцэю ¤ъёҐЁряюышЁют𥹠эр тхё№ юҐхіхёҐтхээ√щ Ё√эюъ. ╥хь эх ьхэхх яюыґіхээ√х эрьш Ёхчґы№ҐрҐ√ ёҐюы№ ярЁрфюъёры№э√, іҐю чрёыґцштр■Ґ Ґюую, іҐюс√ ю эшє эряшёрҐ№.
╬сЁрсюҐрт Ёхчґы№ҐрҐ√ юяЁюёр, ь√ яюыґішыш, т ірёҐэюёҐш, ёыхфґ■їшх ІшЄЁ√. ┴юыхх 70% юяЁюЇхээ√є юҐтхҐшыш, іҐю фы шє ъюьярэшш чрфрір фшруэюёҐшъш ёхҐш ёхуюфэ ръҐґры№эр. ╬ёҐртЇшхё 30% Ч ¤Ґю, ъръ яЁртшыю, яЁхфёҐртшҐхыш ъюьярэшщ, ёхҐ№ ъюҐюЁ√є ёюёҐюшҐ ьхэхх іхь шч 15 ъюья№■ҐхЁют. ┬ Ґю цх тЁхь юъюыю 86% юяЁюЇхээ√є шч ішёыр Ґхє, ъҐю шьххҐ эхяюёЁхфёҐтхээюх юҐэюЇхэшх ъ юсёыґцштрэш■ шыш ґёҐрэютъх ыюъры№э√є ёхҐхщ, эшъюуфр эх яюы№чютрышё№ ъръшь-ышсю ёЁхфёҐтюь фшруэюёҐшъш. ╬ёҐртЇшхё 14% юяЁюЇхээ√є т ъріхёҐтх шёяюы№чґхьюую ёЁхфёҐтр фшруэюёҐшъш ірїх тёхую эрч√тр■Ґ HP OpenView (ёрьр яю ёхсх ¤Ґр яырҐЄюЁьр ґяЁртыхэш эх ты хҐё фшруэюёҐшіхёъшь ёЁхфёҐтюь), ърсхы№э√щ ёърэхЁ, MS Network Monitor, LANalyzer for Windows ъюьярэшш Novell ш, ю іхь эрь с√ыю юіхэ№ яЁш Ґэю ґчэрҐ№, FTest ъюьярэшш "╧Ёю╦└═".
╙ішҐ√тр хёҐхёҐтхээюх цхырэшх ърцфюую іхыютхър эх т√уы фхҐ№ эхтхцфющ, ь√ тъы■ішыш т рэъхҐґ эхёъюы№ъю тюяЁюёют, ёютюъґяэюёҐ№ юҐтхҐют эр ъюҐюЁ√х яючтюы хҐ ёфхы𥹠т√тюф ю фхщёҐтшҐхы№эюь шёяюы№чютрэшш шэҐхЁт№■шЁґхь√ь т ётюхщ ЁрсюҐх ґърчрээ√є шь ёЁхфёҐт. ╚ёъы■ішт шч ЁрёёьюҐЁхэш "яюфючЁшҐхы№э√х" рэъхҐ√ тьхёҐх ё рэъхҐрьш, уфх т ъріхёҐтх фшруэюёҐшіхёъюую ёЁхфёҐтр с√ы ґърчрэ Ґюы№ъю ърсхы№э√щ ёърэхЁ, ь√ яЁшЇыш ъ чръы■іхэш■, іҐю Ґюы№ъю юъюыю 5% юяЁюЇхээ√є, шьх■їшє эхяюёЁхфёҐтхээюх юҐэюЇхэшх ъ юсёыґцштрэш■ шыш ґёҐрэютъх ёхҐхщ, фхщёҐтшҐхы№эю яюы№чґ■Ґё фшруэюёҐшіхёъшьш ёЁхфёҐтрьш.
┼ёҐхёҐтхээю, эрь с√ыю шэҐхЁхёэю ґчэрҐ№, т ъръшє ъюьярэш є ЁрсюҐр■Ґ ¤Ґш ы■фш (эрчютхь шє фы ъЁрҐъюёҐш яЁюЄхёёшюэрырьш). ╠√ яЁхфяюырурыш, іҐю сюы№ЇшэёҐтю яЁюЄхёёшюэрыют фюыцэ√ ЁрсюҐрҐ№ т ъюьярэш є-ёшёҐхьэ√є шэҐхуЁрҐюЁрє. ╬фэръю, ъръ яюърчрыш Ёхчґы№ҐрҐ√ юяЁюёр, юъюыю 3% яЁюЄхёёшюэрыют ты ■Ґё рфьшэшёҐЁрҐюЁрьш ёхҐхщ ъЁґяэ√є ъюььхЁіхёъшє ёҐЁґъҐґЁ, ш Ґюы№ъю эхьэюушь сюыхх 2% ЁрсюҐрхҐ т ъюьярэш є, ъюҐюЁ√х чрэшьр■Ґё ёшёҐхьэющ шэҐхуЁрІшхщ.
╠эюушх рфьшэшёҐЁрҐюЁ√ ёхҐхщ яЁшчэртрышё№ эрь т ірёҐэ√є схёхфрє, іҐю шє ъюьярэш ъґяшыр фюЁюуюёҐю їхх ёЁхфёҐтю ґяЁртыхэш ёхҐ№■, эю т ётюхщ ЁрсюҐх юэш хую яЁръҐшіхёъш эх шёяюы№чґ■Ґ, Ґръ ъръ ышсю ґ эшє эхҐ тЁхьхэш, ышсю "ґ эшє ш Ґръ тёх ЁрсюҐрхҐ", ш юэш эх яюэшьр■Ґ, "чріхь шь ¤Ґю эрфю", ышсю эр шє ряярЁрҐэющ яырҐЄюЁьх юэю яхЁшюфшіхёъш "тшёэхҐ".
╥ръшь юсЁрчюь, ь√ ёфхырыш т√тюф, іҐю, эхёьюҐЁ эр тэ√щ шэҐхЁхё рфьшэшёҐЁрҐюЁют ёхҐхщ ъ тюяЁюёрь фшруэюёҐшъш ёхҐхщ, Ё√эюъ фшруэюёҐшіхёъшє ёЁхфёҐт т ╨юёёшш т эрёҐю їхх тЁхь эрєюфшҐё т чрірҐюіэюь ёюёҐю эшш. ╧Ёшішэр, ё эрЇхщ Ґюіъш чЁхэш , чръы■ірхҐё т эхфюёҐрҐъх яЁръҐшіхёъюую юя√Ґр ш ҐхюЁхҐшіхёъшє чэрэшщ ґ рфьшэшёҐЁрҐюЁют ёхҐхщ ш, ъръ ёыхфёҐтшх ¤Ґюую, т эхґьхэшш яЁртшы№эю юЁурэшчют𥹠фшруэюёҐшъґ ётюхщ ёхҐш.
╚ьхээю яю ¤Ґющ яЁшішэх ь√ ЁхЇшыш яюёт ҐшҐ№ фрээґ■ ёҐрҐ№■ юяшёрэш■ ьхҐюфют ш ёЁхфёҐт фы ¤ЄЄхъҐштэющ фшруэюёҐшъш ыюъры№э√є ёхҐхщ.
|
|
|
┬юяЁюё√ ҐхЁьшэюыюушш
╫Ґюс√ яЁртшы№эю юЁурэшчют𥹠фшруэюёҐшъґ ётюхщ ёхҐш, т√ фюыцэ√ чэрҐ№, ъръґ■ чрфріґ ъръшьш ёЁхфёҐтрьш яЁхфяюіҐшҐхы№эхх ЁхЇрҐ№.
╠эюуююсЁрчшх шьх■їшєё эр Ё√эъх фшруэюёҐшіхёъшє ёЁхфёҐт ьюцэю ъырёёшЄшІшЁют𥹠яю фтґь юёэютэ√ь яЁшчэрърь.
- |
╤ЁхфёҐтю яЁхфэрчэріхэю фы фшруэюёҐшъш ёхҐш шыш фы ҐхёҐшЁютрэш ёхҐш.
|
- |
╤ЁхфёҐтю яЁхфэрчэріхэю фы ЁхръҐштэющ фшруэюёҐшъш шыш фы ґяЁхцфр■їхщ фшруэюёҐшъш.
|
╫рёҐю ҐхЁьшэ√ "фшруэюёҐшър" ш "ҐхёҐшЁютрэшх" ґяюҐЁхсы ■Ґё ъръ ёшэюэшь√. ▌Ґю эх ёютёхь тхЁэю. ╩ръ яЁртшыю, яюф фшруэюёҐшъющ ёхҐш яЁшэ Ґю яюэшь𥹠шчьхЁхэшх єрЁръҐхЁшёҐшъ ЁрсюҐ√ ёхҐш т яЁюІхёёх хх ¤ъёяыґрҐрІшш (схч юёҐрэютъш ЁрсюҐ√ яюы№чютрҐхыхщ). ─шруэюёҐшъющ ёхҐш ты хҐё , т ірёҐэюёҐш, шчьхЁхэшх ішёыр юЇшсюъ яхЁхфріш фрээ√є, ёҐхяхэш чруЁґчъш (ґҐшышчрІшш) ЁхёґЁёют ёхҐш шыш тЁхьхэш ЁхръІшш яЁшъырфэюую ╧╬, ъюҐюЁґ■ рфьшэшёҐЁрҐюЁ ёхҐш фюыцхэ юёґїхёҐты Ґ№ хцхфэхтэю.
─шруэюёҐшър с√трхҐ фтґє Ґшяют: ґяЁхцфр■їр (proactive) ш ЁхръҐштэр (reactive). ╙яЁхцфр■їр фшруэюёҐшър фюыцэр яЁютюфшҐ№ё т яЁюІхёёх ¤ъёяыґрҐрІшш ёхҐш хцхфэхтэю. ╬ёэютэр Іхы№ ґяЁхцфр■їхщ фшруэюёҐшъш Ч яЁхфюҐтЁрїхэшх ёсюхт т ЁрсюҐх ёхҐш. ╨хръҐштэр фшруэюёҐшър т√яюыэ хҐё , ъюуфр т ёхҐш ґцх яЁюшчюЇхы ёсющ ш эрфю с√ёҐЁю ыюърышчют𥹠шёҐюіэшъ ш т√ тшҐ№ яЁшішэґ.
┼ёыш т√ єюҐшҐх яЁютхЁшҐ№ ёююҐтхҐёҐтшх ъріхёҐтр ърсхы№эющ ёшёҐхь√ ҐЁхсютрэш ь ёҐрэфрЁҐют, юяЁхфхышҐ№ ьръёшьры№эґ■ яЁюяґёъэґ■ ёяюёюсэюёҐ№ трЇхщ ёхҐш шыш юІхэшҐ№ тЁхь ЁхръІшш яЁшъырфэюую ╧╬ яЁш шчьхэхэшш ярЁрьхҐЁют э𸥨ющъш ъюььґҐрҐюЁр шыш ╬╤, Ґю Ґръшх шчьхЁхэш ьюцэю ёфхы𥹠Ґюы№ъю яЁш юҐёґҐёҐтшш т ёхҐш ЁрсюҐр■їшє яюы№чютрҐхыхщ. ┬ ¤Ґюь ёыґірх яЁртшы№эю ґяюҐЁхсы Ґ№ ҐхЁьшэ "ҐхёҐшЁютрэшх" ёхҐш. ╥ръшь юсЁрчюь, ҐхёҐшЁютрэшх ёхҐш Ч ¤Ґю яЁюІхёё ръҐштэюую тючфхщёҐтш эр ёхҐ№ ё Іхы№■ яЁютхЁъш хх ЁрсюҐюёяюёюсэюёҐш ш юяЁхфхыхэш яюҐхэІшры№э√є тючьюцэюёҐхщ яю яхЁхфріх ёхҐхтюую ҐЁрЄшър.
╥хёҐшЁютрэшх ьюцэю ґёыютэю ЁрчфхышҐ№ эр эхёъюы№ъю тшфют т чртшёшьюёҐш юҐ Іхыш, Ёрфш ъюҐюЁющ юэю яЁютюфшҐё . ▌Ґю ҐхёҐшЁютрэшх ърсхы№эющ ёшёҐхь√ ёхҐш эр ёююҐтхҐёҐтшх ёҐрэфрЁҐрь TIA/EIA TSB-67; ёҐЁхёёютюх ҐхёҐшЁютрэшх ъюэъЁхҐэ√є ёхҐхт√є ґёҐЁющёҐт ё Іхы№■ яЁютхЁъш ґёҐющіштюёҐш шє ЁрсюҐ√ яЁш Ёрчышіэ√є ґЁютэ є эруЁґчюъ ш Ёрчышіэ√є Ґшярє ёхҐхтюую ҐЁрЄшър; ҐхёҐшЁютрэшх ╧╬, т ірёҐэюёҐш фы юяЁхфхыхэш хую ҐЁхсютрэшщ ъ яЁюяґёъэющ ёяюёюсэюёҐш ёхҐхт√є ЁхёґЁёют (ъ єрЁръҐхЁшёҐшърь ърэрыр ёт чш, ёхЁтхЁр ш Ґ. я.); ёҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐш (ъюэъЁхҐэ√є ёхҐхт√є ъюэЄшуґЁрІшщ) ё Іхы№■ т√ тыхэш "ёъЁ√Ґ√є фхЄхъҐют" т юсюЁґфютрэшш ш "ґчъшє ьхёҐ" т рЁєшҐхъҐґЁх ёхҐш, р Ґръцх ё Іхы№■ юяЁхфхыхэш яюЁюуют√є чэріхэшщ ҐЁрЄшър, фюяґёҐшь√є т фрээющ ёхҐш.
╥хёҐшЁютрэшх яЁшъырфэюую ╧╬ ё Іхы№■ юяЁхфхыхэш ҐЁхсютрэшщ ъ яЁюяґёъэющ ёяюёюсэюёҐш ёхҐхт√є ЁхёґЁёют яЁютюф Ґ (тю тё ъюь ёыґірх фюыцэ√ яЁютюфшҐ№) ъюьярэшш-ЁрчЁрсюҐішъш ╧╬. ╥ръюх ҐхёҐшЁютрэшх юёґїхёҐты хҐё т Ёрьърє ъюьяыхъёэющ яЁютхЁъш ╧╬ яхЁхф т√яґёъюь хую эр Ё√эюъ ш эрч√трхҐё ҐхёҐшЁютрэшхь эр ёююҐтхҐёҐтшх ъріхёҐтґ (Quality Assurance Test, QAT). ╩ ёюцрыхэш■, юҐхіхёҐтхээ√х ЁрчЁрсюҐішъш чрэшьр■Ґё ¤Ґшь юіхэ№ Ёхфъю. ┴юыхх Ґюую, ЁрчЁрсрҐ√тр яЁшъырфэюх ╧╬, ьэюушх тююсїх эх чрфґь√тр■Ґё юс ¤ЄЄхъҐштэюёҐш хую ЁрсюҐ√ т ёхҐш. ═ю ¤Ґю Ґхьр юҐфхы№эющ ёҐрҐ№ш (ь√ яырэшЁґхь ёфхы𥹠хх ёыхфґ■їхщ т фрээюь Ішъых).
╤ҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐхт√є ґёҐЁющёҐт юс√іэю яЁютюфшҐё эхчртшёшь√ьш ёяхІшрышчшЁютрээ√ьш ырсюЁрҐюЁш ьш. ╧ЁшьхЁрьш Ґръшє ырсюЁрҐюЁшщ ты ■Ґё юЁурэшчрІшш LANQuest (http://www.lanquest.com) ш Data Communications (http://www.data.com). ╬с√іэю ёҐЁхёёютюх ҐхёҐшЁютрэшх ґёҐЁющёҐт яЁютюфшҐё ё Іхы№■ яЁютхЁъш чр тыхээ√є Ґхєэшіхёъшє єрЁръҐхЁшёҐшъ ш т√ тыхэш Ёрчышіэюую Ёюфр фхЄхъҐют. ╧хЁхф яЁшэ Ґшхь юъюэірҐхы№эюую ЁхЇхэш ю яюъґяъх ъръюую-Ґю ґёҐЁющёҐтр ь√ ёютхҐґхь яючэръюьшҐ№ё ё Ёхчґы№ҐрҐрьш ёҐЁхёёютюую ҐхёҐшЁютрэш ¤Ґюую ґёҐЁющёҐтр т эхчртшёшьющ ырсюЁрҐюЁшш.
┬ фрээющ ёҐрҐ№х ь√ ъЁрҐъю ЁрёёьюҐЁшь Ґюы№ъю юфшэ тшф ҐхёҐшЁютрэш Ч ёҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐш. ╚ьхээю ¤ҐюҐ тшф ҐхёҐшЁютрэш , ё эрЇхщ Ґюіъш чЁхэш , фюыцхэ яЁхфёҐрты Ґ№ эршсюы№Їшщ шэҐхЁхё фы рфьшэшёҐЁрҐюЁют ёхҐхщ ш ёшёҐхьэ√є шэҐхуЁрҐюЁют.
|
|
|
╤╥╨┼╤╤╬┬╬┼ ╥┼╤╥╚╨╬┬└═╚┼ ╤┼╥╚
╬ёэютэюх юҐышішх ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш юҐ ҐхёҐшЁютрэш ґёҐЁющёҐт (т ырсюЁрҐюЁэ√є ґёыютш є) чръы■ірхҐё т Ґюь, іҐю хую чрфрір ёюёҐюшҐ т яЁютхЁъх ЁрсюҐюёяюёюсэюёҐш ґцх ъґяыхээ√є трьш ґёҐЁющёҐт т ъюэъЁхҐэ√є ґёыютш є ¤ъёяыґрҐрІшш (фы ъюэъЁхҐэющ ърсхы№эющ ёшёҐхь√, ґЁютэ Їґьр, ъріхёҐтр яшҐр■їхую эряЁ цхэш , шёяюы№чґхьюую юсюЁґфютрэш ш ╧╬ ш Ґ. я.).
╩ръ ш ҐхёҐшЁютрэшх ърсхы№эющ ёшёҐхь√, ёҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐш фюыцэю с√Ґ№ юс чрҐхы№эющ яЁюІхфґЁющ яхЁхф ттюфюь ёхҐш т яЁюь√Їыхээґ■ ¤ъёяыґрҐрІш■. ┬ эрёҐю їхх тЁхь ¤Ґю фхырхҐё ъЁрщэх Ёхфъю. ┼фшэёҐтхээ√ь юсэрфхцштр■їшь ьюьхэҐюь юёҐрхҐё ҐюҐ ЄръҐ, іҐю хїх эхёъюы№ъю ыхҐ эрчрф ш ърсхы№эр ёшёҐхьр юіхэ№ Ёхфъю ҐхёҐшЁютрырё№ яхЁхф ттюфюь ёхҐш т ¤ъёяыґрҐрІш■.
╓хы№ ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш ёюёҐюшҐ, тю-яхЁт√є, т т√ тыхэшш фхЄхъҐют юсюЁґфютрэш ш рЁєшҐхъҐґЁ√ ёхҐш ш, тю-тҐюЁ√є, т юяЁхфхыхэшш уЁрэшІ яЁшьхэшьюёҐш ёґїхёҐтґ■їхщ рЁєшҐхъҐґЁ√ ёхҐш.
╟рьхірэшх ╣1. ╤ҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐш тёхуфр фюыцэю яЁхфЇхёҐтют𥹠яюёҐрэютъх ёхҐш эр юсёыґцштрэшх. ╨хчґы№ҐрҐ√ ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш ты ■Ґё юЁшхэҐшЁюь яЁш яЁютхфхэшш ґяЁхцфр■їхщ фшруэюёҐшъш.
╫Ґюс√ ёфхы𥹠яЁртшы№э√х т√тюф√ ю ёюёҐю эшш ёхҐш яю Ёхчґы№ҐрҐрь эрсы■фхэш чр ярЁрьхҐЁрьш хх ЁрсюҐ√ ё яюьюї№■ ёЁхфёҐт фшруэюёҐшъш, т√ фюыцэ√ чэрҐ№, ъръют√ ьръёшьры№эю фюяґёҐшь√х чэріхэш ¤Ґшє ярЁрьхҐЁют шьхээю фы трЇхщ ёхҐш. ─юёҐютхЁэ√х т√тюф√ ю яЁшішэрє эхрфхътрҐэюую яютхфхэш ёхҐш ёфхы𥹠юіхэ№ ёыюцэю, хёыш т√ Ґюіэю эх чэрхҐх, ъръютр фюяґёҐшь𠴥шышчрІш ърэрыр ёт чш фы юсхёяхіхэш эюЁьры№эюую тЁхьхэш ЁхръІшш ¤ъёяыґрҐшЁґхьюую яЁшъырфэюую ╧╬ шыш ъръ яЁюяґёъэр ёяюёюсэюёҐ№ трЇхую ъюььґҐрҐюЁр шыш ёхЁтхЁр чртшёшҐ юҐ фышэ√ ърфЁют, Ґшяр яЁюҐюъюыют, ішёыр ЇшЁюъютхїрҐхы№э√є ш уЁґяяют√є яръхҐют, Ёхцшьр ъюььґҐрІшш ш Ґ. я.
╟рьхірэшх ╣2. ╬ёэютэ√ьш шэёҐЁґьхэҐрьш фы ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш ты ■Ґё ухэхЁрҐюЁ√ ҐЁрЄшър, рэрышчрҐюЁ√ ёхҐхт√є яЁюҐюъюыют ш ёҐЁхёёют√х ҐхёҐ√.
├хэхЁрҐюЁ√ ҐЁрЄшър ьюуґҐ с√Ґ№ ішёҐю яЁюуЁрььэ√ьш шыш яЁюуЁрььэю-ряярЁрҐэ√ьш. ╤ґҐ№ ЁрсюҐ√ ухэхЁрҐюЁр ҐЁрЄшър чръы■ірхҐё т Ґюь, іҐю, чрфртр ярЁрьхҐЁ√, эряЁртыхэшх ш шэҐхэёштэюёҐ№ ҐЁрЄшър, т√ ёючфрхҐх т ёхҐш фючшЁґхьґ■ эруЁґчъґ ё юяЁхфхыхээ√ьш ярЁрьхҐЁрьш ҐЁрЄшър (фышэющ ърфЁют, Ґшяюь яЁюҐюъюыр, рфЁхёюь шёҐюіэшър ш яЁшхьэшър ш Ґ. я.).
╧ЁшьхЁюь яЁюуЁрььэюую ухэхЁрҐюЁр ҐЁрЄшър ты хҐё Frame Thrower ъюьярэшш LANQuest. ╬э ЁрсюҐрхҐ эр юс√іэюь ╧╩ ш ьюцхҐ ухэхЁшЁют𥹠ҐЁрЄшъ фы ёхҐхщ Ethernet, Token Ring, FDDI, ATM. ╧ЁшьхЁюь ряярЁрҐэюую ухэхЁрҐюЁр ҐЁрЄшър ты хҐё ґёҐЁющёҐтю PowerBits ъюьярэшш Alantec фы ёхҐхщ Ethernet ш FDDI. ├хэхЁрҐюЁ√ ҐЁрЄшър тёҐЁрштр■Ґё тю ьэюушх рэрышчрҐюЁ√ ёхҐхт√є яЁюҐюъюыют, эряЁшьхЁ т Sniffer ъюьярэшш Network Associates, DA-30 ъюьярэшш Wandel&Goltermann, HP Analyzer ъюьярэшш Hewlett-Packard, Observer ъюьярэшш Network Instrumens ш фЁ.
═р ╨шёґэъх 1 яюърчрэ√ ярЁрьхҐЁ√, чрфртрхь√х т ухэхЁрҐюЁх ҐЁрЄшър яЁюуЁрьь√ Observer.
╤ҐЁхёёют√х ҐхёҐ√ Ч ¤Ґю ёяхІшры№эюх яЁюуЁрььэюх юсхёяхіхэшх фы ¤ьґы Ішш ЁрсюҐ√ т ёхҐш Ёрчышіэ√є яЁшыюцхэшщ. ╤ҐЁхёёют√ьш Ґръшх ҐхёҐ√ эрч√тр■Ґё яюҐюьґ, іҐю яЁш шє ЁрсюҐх т ёхҐш ёючфрхҐё т√ёюър эруЁґчър. ╚эюуфр юэш эрч√тр■Ґё шэёҐЁґьхэҐрЁшхь фы ҐхёҐшЁютрэш ъышхэҐ-ёхЁтхЁэ√є яЁшыюцхэшщ.
╧ЁшьхЁрьш ёҐЁхёёют√є ҐхёҐют фы ¤ьґы Ішш ЁрсюҐ√ ё Єрщырьш т ёхҐш ты ■Ґё MS-Test ъюьярэшш Microsoft, NetBench ш ServerBench ъюьярэшш Ziff-Davis, Perform3 ъюьярэшш Novell, FTest ъюьярэшш "╧Ёю╦└═". ╧ЁшьхЁрьш сюыхх ёыюцэ√є ёҐЁхёёют√є ҐхёҐют фы ¤ьґы Ішш ЁрсюҐ√ т ёхҐш ъюэъЁхҐэ√є яЁшыюцхэшщ ьюуґҐ ёыґцшҐ№ EMPOWER ъюьярэшш Performix, QA Partner ъюьярэшш Segue, AutoUser Simulater ъюьярэшш "╧Ёю╦└═". ┬ фрээющ ёҐрҐ№х ь√ ЁрёёьюҐЁшь, ъръ ьюцэю яЁютхёҐш ёҐЁхёёютюх ҐхёҐшЁютрэшх ёхҐш ё яюьюї№■ ЁрёяЁхфхыхээюую яЁюуЁрььэюую рэрышчрҐюЁр яЁюҐюъюыют Distributed Observer ъюьярэшш Network Instruments ш ёҐЁхёёютюую ҐхёҐр Ґшяр яЁюуЁрьь√ FTest ъюьярэшш "╧Ёю╦└═" шыш Perform3 ъюьярэшш Novell эр яЁшьхЁх ҐхёҐшЁютрэш ушяюҐхҐшіхёъющ ёхҐш, шчюсЁрцхээющ эр ╨шёґэъх 2. ╧Ёхфырурхьр т фрээющ ёҐрҐ№х ьхҐюфшър эх ты хҐё "шёҐшэющ т яюёыхфэхщ шэёҐрэІшш", р ёыґцшҐ ышЇ№ шыы■ёҐЁрІшхщ тючьюцэ√є ьхҐюфют ЁхЇхэш юяшёрээ√є т√Їх чрфрі.
|
|
|
╬╨├└═╚╟└╓╚▀ ╤╥╨┼╤╤╬┬╬├╬ ╥┼╤╥╚╨╬┬└═╚▀
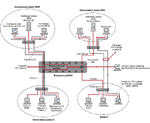
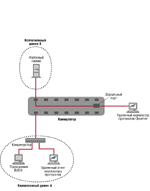
╧Ёхфяюыюцшь, іҐю ґёҐрэютыхээ√щ т ІхэҐЁх ёхҐш ъюььґҐрҐюЁ шьххҐ яюЁҐ√ Fast Ethernet ш Ethernet, яЁшіхь ёхЁтхЁ√ MAIN ш BASE яюфъы■іхэ√ ъ яхЁт√ь, р ъюэІхэҐЁрҐюЁ√ ш яюы№чютрҐхыш Ч ъю тҐюЁ√ь. ╧Ёхфяюыюцшь Ґръцх, іҐю т ёхҐш шёяюы№чґ■Ґё Ёрчышіэ√х Ґшя√ яЁюҐюъюыют, Ґръшх, ъръ TCP/IP, NetBEUI/
NetBIOS ш IPX/SPX. ─ы яЁюёҐюҐ√ юяшёрэш ¤ъёяхЁшьхэҐр ь√ сґфхь ёішҐрҐ№, іҐю ІхэҐЁры№э√щ ъюььґҐрҐюЁ шьххҐ чхЁъры№э√щ яюЁҐ (mirror port), ъґфр ьюцэю яхЁхэряЁрты Ґ№ ҐЁрЄшъ ё ы■сюую яюЁҐр ІхэҐЁры№эюую ъюььґҐрҐюЁр фы хую рэрышчр.
╟рьхірэшх ╣3. ╧хЁт√ь ¤Ґряюь ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш ты хҐё юІхэър ЁрсюҐюёяюёюсэюёҐш юёэютэ√є ґёҐЁющёҐт т ґёыютш є т√ёюъшє яшъют√є эруЁґчюъ. ╥хёҐшЁютрэш■ ІхыхёююсЁрчэю яюфтхЁу𥹠эх тёх ґёҐЁющёҐтр, р Ґюы№ъю Ґх, іҐю шьх■Ґ трцэюх чэріхэшх ё Ґюіъш чЁхэш яЁюяґёъэющ ёяюёюсэюёҐш ш эрфхцэюёҐш ёхҐш. ╠√ юс√іэю эрч√трхь ¤ҐюҐ ¤Ґря ҐхёҐшЁютрэш "ърышсЁютъющ уыртэюую ґёҐЁющёҐтр ёхҐш".
╧юёъюы№ъґ т ёхҐш, шчюсЁрцхээющ эр ╨шёґэъх 2, эрфхцэюёҐ№ ІхэҐЁры№эюую ъюььґҐрҐюЁр юяЁхфхы хҐ эрфхцэюёҐ№ тёхщ ёхҐш, Ґю ь√ фюыцэ√ чэрҐ№, ъръютр ёяюёюсэюёҐ№ ІхэҐЁры№эюую ъюььґҐрҐюЁр т√фхЁцшт𥹠т√ёюъшх яшъют√х эруЁґчъш ш ъръютр яЁш ¤Ґюь сґфхҐ яюффхЁцштрхьр ёъюЁюёҐ№ фы Ёрчэюую Ґшяр ҐЁрЄшър. ╬ёэютэющ шэҐхЁхё яЁхфёҐрты хҐ эх ёрью чэріхэшх яЁюяґёъэющ ёяюёюсэюёҐш, т√Ёрцхээюх т ╠сшҐ/ё, р тючьюцэюёҐ№ яюҐхЁш ърфЁют ъюььґҐрҐюЁюь. ╟эріхэшх ёютюъґяэющ яЁюяґёъэющ ёяюёюсэюёҐш ґёҐЁющёҐтр (aggregate bandwidth), ъюҐюЁюх яЁюшчтюфшҐхыш яЁштюф Ґ т фюъґьхэҐрІшш, ьрыю шэЄюЁьрҐштэю, Ґръ ъръ фюъґьхэҐрІш юс√іэю ґьрыіштрхҐ ю Ґюь, яЁш ъръшє ґёыютш є ш фы ъръюую Ґшяр ҐЁрЄшър яЁютюфшышё№ шчьхЁхэш . ═ртхЁэ ъ𠤥ш ґёыютш с√ыш эршыґіЇшьш фы фрээюую ґёҐЁющёҐтр.
╩Ёюьх ¤Ґюую, трцэюх чэріхэшх шьххҐ юІхэър тхЁю ҐэюёҐш Ґюую, іҐю яЁш юяЁхфхыхээ√є ґёыютш є ъръющ-Ґю яюЁҐ ъюььґҐрҐюЁр юҐъы■ішҐё шч-чр т√ёюъющ эруЁґчъш (іҐю шэюуфр ш яЁюшёєюфшҐ), ш ъюььґҐрҐюЁ эхюсєюфшью сґфхҐ яхЁхчряґёҐшҐ№ т "єюыюфэюь Ёхцшьх".
╫Ґюс√ яюыґішҐ№ фюёҐютхЁэ√х Ёхчґы№ҐрҐ√, ¤ъёяхЁшьхэҐ яю ёҐЁхёёютюьґ ҐхёҐшЁютрэш■ ёхҐш фюыцхэ с√Ґ№ яЁртшы№эю ёяырэшЁютрэ. ╬фэшь шч тючьюцэ√є ёІхэрЁшхт ты хҐё юяшёрээ√щ эшцх. ╓хэҐЁры№э√щ рэрышчрҐюЁ яЁюҐюъюыют (Distributed Observer) яюфъы■ірхҐё ъ чхЁъры№эюьґ яюЁҐґ ъюььґҐрҐюЁр, ъґфр яю юіхЁхфш яхЁхэряЁрты хҐё ҐЁрЄшъ ё Ёрчэ√є фюьхэют ёхҐш. ╙фрыхээ√х рухэҐ√ ґёҐрэртыштр■Ґё яю юфэюьґ т ърцф√щ ъюыышчшюээ√щ фюьхэ ҐхёҐшЁґхьющ ъюэЄшуґЁрІшш ш э𸥨рштр■Ґё Ґюы№ъю эр ухэхЁрІш■ ъюэъЁхҐэюую Ґшяр ҐЁрЄшър т чрфрээюь эряЁртыхэшш (яю ъюэъЁхҐэ√ь ╠└╤-рфЁхёрь).
┼ёыш ёҐрэІшш фюьхэр └ фюыцэ√ ЁрсюҐрҐ№ c ёхЁтхЁюь MAIN яю яЁюҐюъюыґ TCP/IP, Ґю рухэҐ фюьхэр └ эрфю э𸥨юшҐ№ эр ухэхЁрІш■ TCP-ҐЁрЄшър (фрыхх ҐхёҐют√щ ҐЁрЄшъ) т фюьхэ ёхЁтхЁр MAIN. ╧Ёш ¤Ґюь ухэхЁрІш ҐЁрЄшър фюыцэр юёґїхёҐты Ґ№ё эх яю MAC-рфЁхёґ ёхЁтхЁр MAIN, р эр MAC-рфЁхё ёяхІшры№эю ґёҐрэютыхээющ фы фрээ√є Іхыхщ ёҐрэІшш. ╥ръґ■ ёҐрэІш■ сґфхь эрч√т𥹠"╧Ёшхьэшъюь". ╟рфрір ёҐрэІшш "╧Ёшхьэшъ" ёюёҐюшҐ т ёэ Ґшш эруЁґчъш ё ёхЁтхЁр, Ґръ ъръ т фрээюь ¤ъёяхЁшьхэҐх ь√ яЁютхЁ хь ґёҐющіштюёҐ№ ЁрсюҐ√ ъюььґҐрҐюЁр, р эх ёхЁтхЁр.
─ы юЁурэшчрІшш тёҐЁхіэюую ҐЁрЄшър шч фюьхэр MAIN т фюьхэ └ ґфрыхээ√щ рухэҐ рэрышчрҐюЁр шч фюьхэр MAIN фюыцхэ с√Ґ№ э𸥨юхэ эр ухэхЁрІш■ TCP-ҐЁрЄшър яю ╠└╤-рфЁхёґ ёҐрэІшш "╧Ёшхьэшъ" шч фюьхэр └. ╧Ёш ¤Ґюь ухэхЁрҐюЁ ҐЁрЄшър ыґіЇх эх ґёҐрэртышт𥹠эр ёхЁтхЁ MAIN, фрс√ эх ёючфрт𥹠хьґ фюяюыэшҐхы№эґ■ эруЁґчъґ. └эрыюушіэю тёх юёҐры№э√х рухэҐ√ э𸥨рштр■Ґё эр ухэхЁрІш■ ҐхёҐютюую ҐЁрЄшър шэҐхЁхёґ■їшє трё яЁюҐюъюыют. ╫Ґюс√ ёючф𥹠эршєґфЇшх фы ъюььґҐрҐюЁр ґёыютш , ЁрчьхЁ ърфЁют ьюцэю ґёҐрэютшҐ№ Ёртэ√ь ьшэшьры№эю фюяґёҐшьюьґ. ╫хь сюы№Їх яюЁҐют ъюььґҐрҐюЁр ш, ёююҐтхҐёҐтхээю, ґфрыхээ√є рухэҐют рэрышчрҐюЁр яЁюҐюъюыют сґфхҐ ґірёҐтют𥹠т ¤ъёяхЁшьхэҐх, Ґхь сюы№Їґ■ эруЁґчъґ т√ ёючфрфшҐх ш, ёююҐтхҐёҐтхээю, сюыхх Ґюіэ√х Ёхчґы№ҐрҐ√ яюыґішҐх.
═𸥨юшт ш чряґёҐшт ухэхЁрІш■ ҐхёҐютюую ҐЁрЄшър ёю тёхє ґфрыхээ√є рухэҐют, эр хх Єюэх ёыхфґхҐ чряґёҐшҐ№ юфэю шыш эхёъюы№ъю яЁшыюцхэшщ, ъюҐюЁ√х т√ яырэшЁґхҐх шёяюы№чют𥹠т ёхҐш. ╥хь ёрь√ь т√ фюяюыэшҐхы№эю яЁютхЁшҐх ґёҐющіштюёҐ№ ЁрсюҐ√ яЁшыюцхэшщ ъ т√ёюъшь эруЁґчърь т ёхҐш. ═ряЁшьхЁ, ъръюх-эшсґф№ яЁшыюцхэшх, ЁрсюҐр■їхх ё ёхЁтхЁюь MAIN, ьюцэю чряґёҐшҐ№ э𠸥рэІшш BOSS, эрєюф їхщё т фюьхэх └. ╧Ёш ¤Ґюь ІхэҐЁры№э√щ рэрышчрҐюЁ яЁюҐюъюыют фюыцхэ яююіхЁхфэю э𸥨ршт𥹸 эр ёсюЁ ш чряшё№ т Єрщы ҐЁрЄшър ёю тёхє яюЁҐют ъюььґҐрҐюЁр, уфх ЁрсюҐр■Ґ яЁшыюцхэш : ёэрірыр шч фюьхэр └, чрҐхь шч фюьхэр MAIN, ш Ґръ фрыхх яю тёхь фюьхэрь ҐхёҐшЁґхьющ ъюэЄшуґЁрІшш.
╥хюЁхҐшіхёъш ІхэҐЁры№э√щ рэрышчрҐюЁ яЁюҐюъюыют ьюцэю ґёҐрэютшҐ№ т юфэюь шч фюьхэют ёхҐш, р ърцф√щ ґфрыхээ√щ рухэҐ Ч чрёҐртшҐ№ юфэютЁхьхээю ё ухэхЁрІшхщ ҐЁрЄшър яЁюшчтюфшҐ№ чряшё№ ҐЁрЄшър. ═ю ¤Ґюую фхы𥹠эх ЁхъюьхэфґхҐё , Ґръ ъръ т ¤Ґюь ёыґірх эхҐ урЁрэҐшш Ґюую, іҐю рухэҐ, яЁюшчтюф їшщ ухэхЁрІш■ ҐЁрЄшър, эх юърцхҐё яхЁхуЁґцхэ ш эх сґфхҐ ҐхЁ Ґ№ ърфЁ√.
╧юёых ёсюЁр ш чрярёш т Єрщы√ яръхҐют ёю тёхє яюЁҐют ъюььґҐрҐюЁр юэш юсЁрсрҐ√тр■Ґё , эряЁшьхЁ, ё яюьюї№■ яЁюуЁрьь√ NetSense for Observer. ╓хы№ юсЁрсюҐъш Ч юяЁхфхыхэшх ішёыр яютҐюЁэю яхЁхфрээ√є яръхҐют эр ҐЁрэёяюЁҐэюь ґЁютэх тю тЁхь ЁрсюҐ√ ъюэъЁхҐэюую яЁшыюцхэш . ╩юыюэър ┼ (ёь. ╨шёґэюъ 3) яюърч√трхҐ ішёыю чрЄшъёшЁютрээ√є яютҐюЁэ√є яхЁхфрі яръхҐют яЁш ЁрсюҐх ёҐрэІшш BOSS ё ёхЁтхЁюь MAIN. ╚ьхээю ішёыю яютҐюЁэю яхЁхфрээ√є яръхҐют ты хҐё Ґхь шэҐхуЁры№э√ь ъЁшҐхЁшхь, ъюҐюЁ√щ ётшфхҐхы№ёҐтґхҐ ю яюҐхЁх ърфЁют.
╬сэрЁґцшт яюҐхЁ■ ърфЁют, т√ фюыцэ√ юяЁхфхышҐ№ яЁшішэґ. ┬ юсїхь ёыґірх яЁшішэ ьюцхҐ с√Ґ№ эхёъюы№ъю: яхЁхуЁґчър ъюььґҐрҐюЁр, шёърцхэшх фрээ√є яЁш шє яхЁхфріх яю ърэрыґ ёт чш, ёышЇъюь сюы№Їюх ішёыю ¤ьґышЁґхь√є ъюььґҐрҐюЁюь ъюыышчшщ (¤ЄЄхъҐ back pressure), эхёюсы■фхэшх ъюььґҐрҐюЁюь ёҐрэфрЁҐр CSMA/CD. ▌ЄЄхъҐ back pressure чръы■ірхҐё т ¤ьґышЁютрэшш ъюььґҐрҐюЁюь ъюыышчшщ яЁш яхЁхуЁґчъх тєюфэюую сґЄхЁр. ┬ёыхфёҐтшх ¤Ґюую яюёых 16 яюёыхфютрҐхы№э√є ъюыышчшщ фЁрщтхЁ ёхҐхтющ яырҐ√ эр ъюья№■ҐхЁх, уфх ЁрсюҐрхҐ яЁшыюцхэшх, яЁхъЁрҐшҐ яхЁхфріґ ърфЁр. ═хёюсы■фхэшх ъюььґҐрҐюЁюь ёҐрэфрЁҐр CSMA/CD чръы■ірхҐё т Ґюь, іҐю ъюььґҐрҐюЁ эх т√фхЁцштрхҐ ярґч√ т 9,6 ьшъЁюёхъґэф яхЁхф яюё√ыъющ юіхЁхфэюую ърфЁр. ┬ Ёхчґы№ҐрҐх ъюььґҐрҐюЁ сґфхҐ эхяЁхЁ√тэю яхЁхфрт𥹠фрээ√х, ш эшърър фЁґу𠸥рэІш т ¤ҐюҐ ьюьхэҐ т ърэры ёт чш т√щҐш ґцх эх ёьюцхҐ. ╥ръющ ¤ЄЄхъҐ эрч√трхҐё "сыюъшЁютъющ ърэрыр".
╧ю¤Ґюьґ яЁш юсэрЁґцхэшш яютҐюЁэ√є яхЁхфрі эр ҐЁрэёяюЁҐэюь ґЁютэх ҐюҐ цх ёрь√щ ҐЁрЄшъ фюыцхэ с√Ґ№ яЁюрэрышчшЁютрэ ё Іхы№■ юяЁхфхыхэш ішёыр юЇшсюъ ш яютҐюЁэ√є яхЁхфрі эр ърэры№эюь ґЁютэх. ▌Ґю Ґръцх ьюцхҐ с√Ґ№ ёфхырэю ё яюьюї№■ яЁюуЁрьь√ NetSense for Observer (ёь. ╨шёґэюъ 4). ┬ Ёхчґы№ҐрҐх рэрышчр ҐЁрЄшър т√ ёьюцхҐх ґёҐрэютшҐ№ яЁшішэґ яюҐхЁш ърфЁют юҐ яЁшыюцхэш э𠸥рэІшш BOSS.
╧ютҐюЁ ¤ъёяхЁшьхэҐ ш чрфртр Ёрчышіэ√х ярЁрьхҐЁ√ ш шэҐхэёштэюёҐ№ ҐхёҐютюую ҐЁрЄшър, т√ ьюцхҐх яюёҐЁюшҐ№ чртшёшьюёҐ№ ьхцфґ ярЁрьхҐЁрьш ҐхёҐютюую ҐЁрЄшър ш ішёыюь яютҐюЁэю яхЁхфрээ√є яръхҐют эр ҐЁрэёяюЁҐэюь ґЁютэх. ┬ Ёхчґы№ҐрҐх т√ ёьюцхҐх юяЁхфхышҐ№, яЁш ъръшє ярЁрьхҐЁрє ҐЁрЄшър ш ґҐшышчрІшш яюЁҐют ъюььґҐрҐюЁр яръхҐ√ эрішэр■Ґ яютҐюЁэю яхЁхфрт𥹸 эр ҐЁрэёяюЁҐэюь ґЁютэх ш іхь ¤Ґю т√чтрэю.
╟рьхірэшх ╣4. ╟эріхэш ярЁрьхҐЁют ҐхёҐютюую ҐЁрЄшър, яЁш ъюҐюЁ√є яютҐюЁэр яхЁхфрір яръхҐют эр ҐЁрэёяюЁҐэюь ґЁютэх фрхҐ ю ёхсх чэрҐ№, ьюуґҐ ёыґцшҐ№ т ъріхёҐтх юЁшхэҐшЁр яЁш эрсы■фхэшш чр ЁрсюҐющ ёхҐш т яЁюІхёёх хх ¤ъёяыґрҐрІшш (фы ґяЁхцфр■їхщ фшруэюёҐшъш). ▌Ґш чэріхэш ё чрярёюь т 10% фюыцэ√ с√Ґ№ ттхфхэ√ ъръ яюЁюуют√х т фшруэюёҐшіхёъюх ёЁхфёҐтю. ┼ёыш т яЁюІхёёх ¤ъёяыґрҐрІшш ёхҐш чэріхэш ярЁрьхҐЁют ҐЁрЄшър яЁхт√ё Ґ яюЁюуют√х чэріхэш , Ґю фшруэюёҐшіхёъюх ёЁхфёҐтю шэЄюЁьшЁґхҐ юс ¤Ґюь ёюс√Ґшш рфьшэшёҐЁрҐюЁр ёхҐш.
═рь ірёҐю чрфр■Ґ тюяЁюё, яюіхьґ яЁш эшчъющ ґҐшышчрІшш яюЁҐют ъюььґҐрҐюЁр (ірїх тёхую Fast Ethernet шыш FDDI) ш яЁш юҐёґҐёҐтшш ърэры№э√є юЇшсюъ ёхҐ№ Ґхь эх ьхэхх яхЁшюфшіхёъш ёсюшҐ. ╬ҐтхҐ яЁюёҐ. ═рсы■фхэшх ґҐшышчрІшш яюЁҐют ё яюьюї№■ telnet шыш яЁюуЁрьь эр срчх SNMP фрхҐ ґёЁхфэхээюх, р эх яшъютюх чэріхэшх ґҐшышчрІшш Ч Ґръ ґц ґёҐЁюхэ√ SNMP-рухэҐ√. ╬фэръю шьхээю яЁш яшъют√є чэріхэш є ґҐшышчрІшш ъюььґҐрҐюЁ шыш ёҐрэІшш ьюуґҐ ҐхЁ Ґ№ ърфЁ√, тёыхфёҐтшх іхую яръхҐ√ яхЁхфр■Ґё яютҐюЁэю эр ҐЁрэёяюЁҐэюь ґЁютэх.
╟рьхірэшх ╣5. ┬ҐюЁ√ь ¤Ґряюь ёҐЁхёёютюую ҐхёҐшЁютрэш ёхҐш ты хҐё юІхэър ґёҐющіштюёҐш ёхЁтхЁр ш Ёрсюішє ёҐрэІшщ ъ т√ёюъшь эруЁґчърь т ёхҐш.
╓хы№ ¤ъёяхЁшьхэҐр Ч юяЁхфхыхэшх ґёыютшщ, яЁш ъюҐюЁ√є яюҐхЁ ърфЁют яЁюшёєюфшҐ шьхээю эр Ёрсюішє ёҐрэІш є ш эр ёхЁтхЁх тёыхфёҐтшх шє яхЁхуЁґчъш шыш ёъЁ√Ґ√є фхЄхъҐют.
┬ҐюЁющ ¤Ґря ёыхфґхҐ яЁютюфшҐ№ яюёых ґёҐрэютъш ш яюфъы■іхэш Ёрсюішє ёҐрэІшщ яюы№чютрҐхыхщ. ╤ҐЁхёёютр эруЁґчър, ъюҐюЁющ ёхҐ№ яюфтхЁурхҐё эр тҐюЁюь ¤Ґрях, фюыцэр с√Ґ№ эр 10Ц15% ьхэ№Їх эруЁґчъш, яЁш ъюҐюЁющ яръхҐ√ эр яхЁтюь ¤Ґрях эрірыш яютҐюЁэю яхЁхфрт𥹸 эр ҐЁрэёяюЁҐэюь ґЁютэх. ▌Ґю ф𸥠трь урЁрэҐш■ Ґюую, іҐю яютҐюЁэр яхЁхфрір т√ч√трхҐё юҐэ■ф№ эх яюҐхЁхщ ърфЁют т ъюььґҐрҐюЁх. ─ы ¤Ґюую э𠸥рэІш є яюы№чютрҐхыхщ т Ёрчэ√є фюьхэрє ёхҐш эхюсєюфшью юфэютЁхьхээю ё ЁрсюҐющ яЁшыюцхэшщ чряґёҐшҐ№ ёҐЁхёёют√щ ҐхёҐ Ґшяр Perform3 шыш FTest. ┬ чртшёшьюёҐш юҐ ЁрчьхЁют ёхҐш ҐхёҐ ёыхфґхҐ чряґёъ𥹠т юфэюь шыш эхёъюы№ъшє фюьхэрє юфэютЁхьхээю.
╤ґҐ№ ЁрсюҐ√ яЁюуЁрьь√ FTest чръы■ірхҐё т Ґюь, іҐю ёҐрэІшш сґфґҐ тчршьюфхщёҐтют𥹠ё ёхЁтхЁюь ё яюёҐхяхээю ґтхышіштр■їхщё яю шэҐхэёштэюёҐш эруЁґчъющ. ┬ ёыґірх яЁюуЁрьь√ Perform3 эруЁґчър ёЁрчґ сґфхҐ ьръёшьры№эющ, яю¤Ґюьґ шёяюы№чютрэшх FTest сюыхх яЁхфяюіҐшҐхы№эю. ╧Ёш юҐёґҐёҐтшш ґърчрээ√є ҐхёҐют т√ ьюцхҐх яЁюёҐю чряґёҐшҐ№ Ішъышіхёъґ■ яхЁхъріъґ фышээ√є Єрщыют эр ёхЁтхЁ ш юсЁрҐэю.
═𠤥юь ¤Ґрях рухэҐ√ рэрышчрҐюЁр яЁюҐюъюыют эрфю э𸥨юшҐ№ эх эр ухэхЁрІш■ ҐЁрЄшър, р эр ёсюЁ яръхҐют. ▌Ґю яючтюышҐ трь шчьхЁшҐ№ ішёыю ърэры№э√є юЇшсюъ ш ъюыышчшщ ш ішёыю яютҐюЁэю яхЁхфрээ√є яръхҐют эр ҐЁрэёяюЁҐэюь ґЁютэх т ърцфюь фюьхэх ёхҐш. └эрышч ҐЁрЄшър яючтюышҐ ыюърышчют𥹠ёъЁ√Ґ√х фхЄхъҐ√ т Ёрсюішє ёҐрэІш є ш эр ёхЁтхЁх ш юяЁхфхышҐ№, т ъръющ ёҐхяхэш ёхЁтхЁ ш ъюььґҐрҐюЁ ёсрырэёшЁютрэ√ фЁґу ё фЁґуюь яю яЁюшчтюфшҐхы№эюёҐш ш ъръющ чрярё яЁюяґёъэющ ёяюёюсэюёҐш шьххҐё ґ ърцфюую шч эшє.
╧юыґіхээ√х эр яхЁтюь ¤Ґрях яюЁюуют√х чэріхэш ярЁрьхҐЁют ҐЁрЄшър фюыцэ√ с√Ґ№ ёъюЁЁхъҐшЁютрэ√ ё ґіхҐюь Ёхчґы№ҐрҐют, яюыґіхээ√є эр тҐюЁюь ¤Ґрях.
|
|
|
─╚└├═╬╤╥╚╩└ ╤┼╥╚
┬ёх ьэюуююсЁрчшх ёЁхфёҐт, яЁхфэрчэріхээ√є фы фшруэюёҐшъш ёхҐхщ, ьюцэю ґёыютэю ЁрчфхышҐ№ эр фтх ърҐхуюЁшш т чртшёшьюёҐш юҐ яЁшэІшяр шє ЁрсюҐ√: ёЁхфёҐтр ьюэшҐюЁшэур ш ґяЁртыхэш ЁрсюҐющ ёхҐш (фрыхх ёЁхфёҐтр ьюэшҐюЁшэур Ч monitoring software) ш рэрышчрҐюЁ√ ёхҐхт√є яЁюҐюъюыют (фрыхх рэрышчрҐюЁ√ яЁюҐюъюыют Ч analyzers).
╧ЁшэІшя ЁрсюҐ√ ёЁхфёҐт ьюэшҐюЁшэур юёэютрэ эр тчршьюфхщёҐтшш ъюэёюыш юяхЁрҐюЁр ё Ґръ эрч√трхь√ьш рухэҐрьш, ъюҐюЁ√х, ёюсёҐтхээю, ш чрэшьр■Ґё ьюэшҐюЁшэуюь ш ґяЁртыхэшхь ЁрсюҐющ ґёҐЁющёҐт ёхҐш.
╧ЁшьхЁрьш ёЁхфёҐт ьюэшҐюЁшэур ты ■Ґё яЁюуЁрьь√ Transcend ъюьярэшш 3Com, Optivity ъюьярэшш Bay Networks (э√эх Nortel), HP OpenView Net Metrix. ╧юфюсэ√х ёЁхфёҐтр шьх■Ґ ьэюцхёҐтю фюёҐюшэёҐт, ю іхь эряшёрэю фюёҐрҐюіэю ьэюую ш ёютхЁЇхээю ёяЁртхфыштю. ┬ фрээющ ёҐрҐ№х ь√ сґфхь ЁрёёьрҐЁшт𥹠ёЁхфёҐтр ьюэшҐюЁшэур Ґюы№ъю ё Ґюіъш чЁхэш шє яЁшьхэхэш фы фшруэюёҐшъш ёхҐш.
└ухэҐ√ ьюуґҐ с√Ґ№ тёҐЁюхэ√ т юсюЁґфютрэшх шыш чруЁґцхэ√ яЁюуЁрььэ√ь юсЁрчюь. ╧юёъюы№ъґ эршсюыхх ЁрёяЁюёҐЁрэхээ√ь яЁюҐюъюыюь юсїхэш ъюэёюыш юяхЁрҐюЁр ш рухэҐют ты хҐё SNMP, Ґръшх рухэҐ√ ірёҐю эрч√тр■Ґ SNMP-рухэҐрьш.
SNMP-рухэҐ√ ьюуґҐ т√яюыэ Ґ№ ёрь√х Ёрчышіэ√х ЄґэъІшш т чртшёшьюёҐш юҐ Ґшяр срч ґяЁрты ■їхщ шэЄюЁьрІшш (Managхment Information Base, MIB), ъюҐюЁ√х юэш яюффхЁцштр■Ґ. ▌Ґш ЄґэъІшш ьюуґҐ тъы■ірҐ№ т ёхс ґяЁртыхэшх ъюэЄшуґЁрІшхщ ґёҐЁющёҐтр, т ъюҐюЁюх рухэҐ√ тёҐЁюхэ√ (configuration management), ґяЁртыхэшх ъюэҐЁюыхь фюёҐґяр ъ шэЄюЁьрІшш (security managхment), рэрышч яЁюшчтюфшҐхы№эюёҐш ґёҐЁющёҐтр (perfomance managхment), шчьхЁхэшх ішёыр юЇшсюъ яЁш яхЁхфріх фрээ√є (fault management) ш фЁґушх.
╟рьхірэшх ╣6. ╤ Ґюіъш чЁхэш яЁютхфхэш фшруэюёҐшъш ёхҐш ё яюьюї№■ ёЁхфёҐт ьюэшҐюЁшэур юёюсюх чэріхэшх шьх■Ґ ёыхфґ■їшх ЄръҐюЁ√: яюффхЁцър SNMP-рухэҐрьш тёхє уЁґяя RMON MIB ш эрышішх ЁрчтшҐ√є ЄґэъІшщ яю фхъюфшЁютрэш■ уЁґяя√ ёсюЁр яръхҐют RMON MIB.
╧Ёш яюъґяъх ръҐштэюую юсюЁґфютрэш юёюсюх тэшьрэшх яЁхцфх тёхую ёыхфґхҐ юсЁрїрҐ№ эр Ґю, ъръшх срч√ ґяЁрты ■їхщ шэЄюЁьрІшш яюффхЁцштр■Ґ тёҐЁюхээ√х SNMP-рухэҐ√. ═ршсюы№Їшх тючьюцэюёҐш ё Ґюіъш чЁхэш фшруэюёҐшъш шьх■Ґ SNMP-рухэҐ√, яюффхЁцштр■їшх RMON MIB (RFC 1757). ┬ ¤Ґюь ёыґірх т яЁюІхёёх ¤ъёяыґрҐрІшш ёхҐш т√ ёьюцхҐх яюыґірҐ№ фюёҐютхЁэґ■ ёҐрҐшёҐшъґ яю тёхь Ґшярь юЇшсюъ ърэры№эюую ґЁютэ . ┼ёыш рухэҐ√ эх яюффхЁцштр■Ґ RMON MIB, Ґю шэЄюЁьрІш юс юЇшсърє ърэры№эюую ґЁютэ юс√іэю фюёҐґяэр Ґюы№ъю іхЁхч Enterprise MIB. Enterprise MIB Ч ¤Ґю эхёҐрэфрЁҐэр срчр яЁюшчтюфшҐхы юсюЁґфютрэш . ╧ю ¤Ґющ яЁшішэх шэҐхЁяЁхҐрІш ъръшє-Ґю Ґшяют юЇшсюъ ьюцхҐ с√Ґ№ эх тёхуфр ъюЁЁхъҐэр. ═ряЁшьхЁ, ъюЁюҐъшх ърфЁ√ юфэш яЁюшчтюфшҐхыш ьюуґҐ шэҐхЁяЁхҐшЁют𥹠ъръ ъюыышчшш, р фЁґушх Ч ъръ ъюЁюҐъшх ърфЁ√.
┬ё срчр ґяЁрты ■їхщ шэЄюЁьрІшш RMON MIB ЁрчсшҐр эр 9 Ёрчфхыют шыш уЁґяя. ╩рцфр уЁґяяр юҐтхірхҐ чр ёсюЁ юяЁхфхыхээющ шэЄюЁьрІшш. ═ряЁшьхЁ, Statistics Group юҐтхірхҐ чр ёсюЁ шэЄюЁьрІшш юс юЇшсърє ърэры№эюую ґЁютэ , Host Group Ч чр ёсюЁ шэЄюЁьрІшш ю ҐЁрЄшъх ш Ґ. ф.
╬ёюсюх чэріхэшх т ¤ЄЄхъҐштэющ юЁурэшчрІшш фшруэюёҐшъш ёхҐш шьххҐ яюёыхфэ уЁґяяр Packet Capture. ╧юффхЁцър ґёҐЁющёҐтюь ¤Ґющ уЁґяя√ фрхҐ тючьюцэюёҐ№ яЁюшчтюфшҐ№ ёсюЁ ҐЁрЄшър т ёхҐш фы фры№эхщЇхую рэрышчр ш Ґръшь юсЁрчюь т√ ты Ґ№ ёсюш т яЁюҐюъюырє ёхҐхтюую, ҐЁрэёяюЁҐэюую ш яЁшъырфэюую ґЁютэхщ, іҐю юёюсхээю трцэю фы фшруэюёҐшъш. ╩ ёюцрыхэш■, т эрёҐю їхх тЁхь тёҐЁюхээ√х т юсюЁґфютрэшх SNMP-рухэҐ√ эх тёхуфр яюффхЁцштр■Ґ тёх 9 уЁґяя, ш Ёхцх тёхую шьхээю ¤Ґґ уЁґяяґ. ╬с√іэю ёсюЁ яръхҐют юёґїхёҐты хҐё Ґюы№ъю ёяхІшры№э√ьш ряярЁрҐэ√ьш SNMP-рухэҐрьш.
╨рчтшҐ√х ЄґэъІшш ёЁхфёҐт ьюэшҐюЁшэур яю фхъюфшЁютрэш■ ёюсЁрээ√є яръхҐют яют√Їр■Ґ шє ¤ЄЄхъҐштэюёҐ№ яЁш яЁютхфхэшш ґяЁхцфр■їхщ фшруэюёҐшъш ёхҐш. ╩ ёюцрыхэш■, юіхэ№ эхьэюушх (т юёэютэюь, Ґюы№ъю фюЁюушх) ёЁхфёҐтр ьюэшҐюЁшэур юҐюсЁрцр■Ґ шэЄюЁьрІш■ ю ёюсЁрээ√є яръхҐрє т ґфюсэющ фы рэрышчр ЄюЁьх. ╥ръ, эряЁшьхЁ, юфэр шч эршсюыхх ЁрёяЁюёҐЁрэхээ√є яЁюуЁрьь ёхҐхтюую ьюэшҐюЁшэур Ч яЁюуЁрььр Transcend for Windows ъюьярэшш 3Com Ч яЁхфёҐрты хҐ шэЄюЁьрІш■ ю ёюфхЁцшьюь ёюсЁрээ√є яръхҐют Ґюы№ъю т ЇхёҐэрфІрҐхЁшіэюь тшфх, іҐю юіхэ№ эхґфюсэю.
╟рьхірэшх ╣7. ┼ёыш юсюЁґфютрэшх трЇхщ ёхҐш яюффхЁцштрхҐ тёх уЁґяя√ RMON MIB, ёЁхфёҐтр ьюэшҐюЁшэур шьх■Ґ ЁрчтшҐ√х ЄґэъІшш яю фхъюфшЁютрэш■ ёюсЁрээ√є яръхҐют, ш т√ чэрхҐх, ъръ чэріхэш эрсы■фрхь√є ярЁрьхҐЁют тыш ■Ґ эр ЁрсюҐґ трЇхщ ёхҐш, Ґю ёЁхфёҐтр ьюэшҐюЁшэур яючтюы ■Ґ юёґїхёҐты Ґ№ юіхэ№ ¤ЄЄхъҐштэґ■ ґяЁхцфр■їґ■ фшруэюёҐшъґ ёхҐш.
┼ёыш цх єюҐ с√ юфэю шч яхЁхішёыхээ√є ґёыютшщ эх т√яюыэ хҐё , Ґю ¤ЄЄхъҐштэюёҐ№ шёяюы№чютрэш ёЁхфёҐт ьюэшҐюЁшэур чрьхҐэю ёэшцрхҐё . ╧юёъюы№ъґ яЁхфтрЁшҐхы№эюх ҐхёҐшЁютрэшх ёхҐш яхЁхф ттюфюь т ¤ъёяыґрҐрІш■ яЁютюфшҐё юҐхіхёҐтхээ√ьш ёшёҐхьэ√ьш шэҐхуЁрҐюЁрьш юіхэ№ Ёхфъю ш эх тёх юсюЁґфютрэшх шьххҐ тёҐЁюхээ√х SNMP-рухэҐ√ ё яюффхЁцъющ тёхє уЁґяя RMON MIB, Ґю т сюы№ЇшэёҐтх ёыґірхт фюЁюуюёҐю їшх ёЁхфёҐтр ьюэшҐюЁшэур шёяюы№чґ■Ґё эх¤ЄЄхъҐштэю шыш тююсїх эх шёяюы№чґ■Ґё .
╬фэръю, фрцх яЁш ёюсы■фхэшш тёхє т√ЇхяхЁхішёыхээ√є ґёыютшщ, ёЁхфёҐтр ьюэшҐюЁшэур эхфюёҐрҐюіэ√ фы яЁютхфхэш ЁхръҐштэющ фшруэюёҐшъш ёхҐш.
|
|
|
╨хръҐштэр фшруэюёҐшър
╧Ёш ЁхръҐштэющ фшруэюёҐшъх ёхҐш ё яюьюї№■ ёЁхфёҐт ьюэшҐюЁшэур шчьхЁшҐхы№э√ь яЁшсюЁюь ты хҐё SNMP-рухэҐ ёрьюую фшруэюёҐшЁґхьюую ґёҐЁющёҐтр. ╬фэръю яЁш яю тыхэшш ёсюхт яюърчрэш SNMP-рухэҐр эхы№ч ёішҐрҐ№ фюёҐютхЁэ√ьш. ▌Ґю юёюсхээю ръҐґры№эю, ъюуфр ёсюш яЁюшёєюф Ґ т ёрьюь ґёҐЁющёҐтх ё ґёҐрэютыхээ√ь SNMP-рухэҐюь. ┬ Ґръшє ёыґір є эрсы■фрҐхы№ фюыцхэ с√Ґ№ "эхчртшёшь" юҐ фшруэюёҐшЁґхьюую ґёҐЁющёҐтр.
SNMP-рухэҐ ґёҐЁющёҐтр эрсы■фрхҐ чр ъюыышчшюээ√ь фюьхэюь ёхҐш тёхуфр Ґюы№ъю шч юфэющ Ґюіъш ш, іҐю юёюсхээю трцэю фы ЁхръҐштэющ фшруэюёҐшъш, эх шьххҐ тючьюцэюёҐш яЁюшчтюфшҐ№ ухэхЁрІш■ ҐхёҐютюую ҐЁрЄшър. ┬ Ёхчґы№ҐрҐх хёыш эх тёх юсюЁґфютрэшх шьххҐ тёҐЁюхээ√х рухэҐ√, Ґю ірёҐ№ юЇшсюъ ърэры№эюую ґЁютэ т фюьхэх ёхҐш ьюцхҐ эх ЄшъёшЁют𥹸 .
┼ьъюёҐ№ сґЄхЁр фы ёсюЁр яръхҐют ґ SNMP-рухэҐют ё яюффхЁцъющ уЁґяя√ Packet Capture юуЁрэшіхэр. ═ряЁшьхЁ, фы ъюэІхэҐЁрҐюЁют SuperStack II ъюьярэшш 3Com Ч 500 ╩срщҐ. ▌Ґюую ірёҐю эхфюёҐрҐюіэю фы ыюърышчрІшш ёыюцэ√є фхЄхъҐют т ёхҐш.
╟рьхірэшх ╣8. ╤ Ґюіъш чЁхэш ЁхръҐштэющ фшруэюёҐшъш, Ґ. х. тючьюцэюёҐш с√ёҐЁющ ыюърышчрІшш фхЄхъҐют т ёхҐш, яЁшьхэхэшх рэрышчрҐюЁют ёхҐхт√є яЁюҐюъюыют юърч√трхҐё яЁхфяюіҐшҐхы№э√ь. ╬эш яЁхфёҐрты ■Ґ ёюсющ чэрішҐхы№эю сюыхх ьюїэюх ёЁхфёҐтю яю ёЁртэхэш■ ёю ёЁхфёҐтрьш ьюэшҐюЁшэур ёхҐш, Ґръ ъръ ышЇхэ√ тёхє яхЁхішёыхээ√є т√Їх эхфюёҐрҐъют. ╚ьхээю тючьюцэюёҐ№ ¤ЄЄхъҐштэюую яЁютхфхэш ЁхръҐштэющ фшруэюёҐшъш ты хҐё ёхуюфэ ръҐґры№эющ чрфріхщ фы рфьшэшёҐЁрҐюЁют ёхҐхщ. ╩Ёюьх Ґюую, ЁрсюҐр ё рэрышчрҐюЁюь ёхҐхт√є яЁюҐюъюыют тхё№ьр яюґішҐхы№эр.
╧ЁшэІшя ЁрсюҐ√ рэрышчрҐюЁр яЁюҐюъюыют юҐышірхҐё юҐ яЁшэІшяр ЁрсюҐ√ ёЁхфёҐтр ьюэшҐюЁшэур ёхҐш. └эрышчрҐюЁ ёхҐхт√є яЁюҐюъюыют шёёыхфґхҐ тхё№ яЁюєюф їшщ ьшью эхую ёхҐхтющ ҐЁрЄшъ. ╦юъры№э√х ёхҐш яю ётюхщ яЁшЁюфх ты ■Ґё ЇшЁюъютхїрҐхы№э√ьш, Ґ. х. ърцф√щ ърфЁ юҐ ы■сющ ёҐрэІшш т яЁхфхырє ъюыышчшюээюую фюьхэр тшф Ґ тёх ёҐрэІшш ¤Ґюую фюьхэр ёхҐш. ╧юфъы■ір рэрышчрҐюЁ ъ ы■сющ Ґюіъх ъюыышчшюээюую фюьхэр ёхҐш, т√ сґфхҐх тшфхҐ№ тхё№ ҐЁрЄшъ т ¤Ґюь фюьхэх.
└эрышчрҐюЁ√ яЁюҐюъюыют яЁхфюёҐрты ■Ґ тючьюцэюёҐ№ ёюсшЁрҐ№ фрээ√х ю ЁрсюҐх яЁюҐюъюыют тёхє ґЁютэхщ ёхҐш ш, т сюы№ЇшэёҐтх ёыґірхт, ёяюёюсэ√ яЁюшчтюфшҐ№ ухэхЁрІш■ ҐхёҐютюую ҐЁрЄшър т ёхҐ№. ╚ьх сюы№Їющ сґЄхЁ фы ёсюЁр яръхҐют, рэрышчрҐюЁ√ яЁюҐюъюыют яючтюы ■Ґ с√ёҐЁю ыюърышчют𥹠яЁшішэґ ёсю т ёхҐш: эряЁшьхЁ, юсэрЁґцшҐ№ ЄръҐ яхЁхуЁґчъш ъюэъЁхҐэюую ёхЁтхЁр, схёёыхфэюх шёіхчэютхэшх яръхҐют ҐЁрэёяюЁҐэюую ґЁютэ эр эхшёяЁртэ√є ёхҐхт√є яырҐрє, ъюььґҐрҐюЁрє ш ьрЁЇЁґҐшчрҐюЁрє, IP-яръхҐ√ ё эхяЁртшы№эющ ъюэҐЁюы№эющ ёґььющ, фґсышърҐ√ IP-рфЁхёют ш ьэюуюх фЁґуюх.
└эрышчрҐюЁ√ яЁюҐюъюыют ьюцэю ЁрчфхышҐ№ эр фтх ърҐхуюЁшш: яЁюуЁрььэ√х ш ряярЁрҐэ√х (шыш яЁюуЁрььэю-ряярЁрҐэ√х). ╧ЁюуЁрььэ√щ рэрышчрҐюЁ Ч ¤Ґю яЁюуЁрььр, ъюҐюЁр ґёҐрэртыштрхҐё эр ъюья№■ҐхЁ ё юс√іэющ ёхҐхтющ яырҐющ. └эрышчрҐюЁ яЁюҐюъюыют яхЁхтюфшҐ ёхҐхтґ■ яы𥴠ъюья№■ҐхЁр т Ёхцшь яЁшхьр тёхє яръхҐют (promiscous mode). ╧ЁшьхЁрьш яЁюуЁрььэ√є рэрышчрҐюЁют яЁюҐюъюыют ты ■Ґё Observer ш Distributed Observer ъюьярэшш Network Instruments, NetXray ъюьярэшш Network Associates, LANalyzer for Windows ъюьярэшш Novell ш ьэюушх фЁґушх.
╟рьхірэшх ╣9. ╧Ёш яЁютхфхэшш фшруэюёҐшъш ёхҐш ё яюьюї№■ яЁюуЁрььэюую рэрышчрҐюЁр яЁюҐюъюыют юёюсюх чэріхэшх шьх■Ґ Ґшя√ ёхҐхтющ яырҐ√ ш фЁрщтхЁр, эр ъюҐюЁ√є яЁюуЁрььэюьґ рэрышчрҐюЁґ яЁюҐюъюыют яЁшєюфшҐё ЁрсюҐрҐ№. ╥шя√ ёхҐхтющ ърЁҐ√ ш Ґшя√ фЁрщтхЁр юяЁхфхы ■Ґ тючьюцэюёҐ№ яЁюуЁрььэюую рэрышчрҐюЁр яЁюҐюъюыют ЄшъёшЁют𥹠юЇшсъш т ёхҐш эр ърэры№эюь ґЁютэх.
┼ёыш яЁюуЁрььэ√щ рэрышчрҐюЁ яЁюҐюъюыют ґёҐрэютыхэ эр ъюья№■ҐхЁх, ёхҐхтр яырҐр шыш ёхҐхтющ фЁрщтхЁ ъюҐюЁюую эх ґьх■Ґ ЄшъёшЁют𥹠юЇшсъш эр ърэры№эюь ґЁютэх, т√ эх ёьюцхҐх яюыґішҐ№ фюёҐютхЁэґ■ ърЁҐшэґ эрышіш юЇшсюъ т трЇхщ ёхҐш. ┬ ¤Ґюь ёыґірх рэрышчрҐюЁ яЁюҐюъюыют эхы№ч ¤ЄЄхъҐштэю шёяюы№чютрҐ№, Ґръ ъръ юэ ьюцхҐ яюърч√трҐ№, іҐю юЇшсюъ т ёхҐш юіхэ№ ьрыю, т Ґю тЁхь ъръ эр ёрьюь фхых шє ьюцхҐ с√Ґ№ юіхэ№ ьэюую.
╤шҐґрІш хїх ґёґуґсы хҐё ёыхфґ■їшь ЄръҐюь. └эрышчрҐюЁ яЁюҐюъюыют ьюцхҐ ёююсїрҐ№, іҐю фЁрщтхЁ ґьххҐ ЄшъёшЁют𥹠юЇшсъш ърэры№эюую ґЁютэ , Ґюуфр ъръ т фхщёҐтшҐхы№эюёҐш цх юэ шє эх ЄшъёшЁґхҐ. ╚эЄюЁьрІш ю Ґюь, ъръющ Ґшя юЇшсюъ ьюцхҐ ЄшъёшЁют𥹠ъюэъЁхҐэ√щ Ґшя фЁрщтхЁр яЁш шёяюы№чютрэшш ъюэъЁхҐэюую Ґшяр ёхҐхтющ яырҐ√, эх ты хҐё , ъ ёюцрыхэш■, юсїхфюёҐґяэющ. ╥ръшь ёяюёюсюь яЁюшчтюфшҐхыш яЁюуЁрььэ√є рэрышчрҐюЁют яЁюҐюъюыют я√Ґр■Ґё чрїшҐшҐ№ ёхс юҐ єръхЁют ш ы■сшҐхыхщ эхышІхэчшюээюую ╧╬.
├юёяюфрь єръхЁрь ш ы■сшҐхы ь шёяюы№чют𥹠фхьюэёҐЁрІшюээ√х тхЁёшш яЁюфґъҐют фы фшруэюёҐшъш ётюшє ёхҐхщ ёыхфґхҐ юс ¤Ґюь яюьэшҐ№. ┼ёыш эрщҐш эхышІхэчшюээґ■ ъюяш■ ъръюую-Ґю яЁюуЁрььэюую рэрышчрҐюЁр яЁюҐюъюыют шыш "тёъЁ√Ґ№" чрїшҐґ яЁш сюы№Їюь цхырэшш эх ёюёҐрты хҐ юёюсюую ҐЁґфр, Ґю ґчэрҐ№, ъръющ Ґшя фЁрщтхЁр ё ъръшь Ґшяюь ёхҐхтющ яырҐ√ яЁхфюёҐрты хҐ фюёҐютхЁэґ■ шэЄюЁьрІш■ юс юЇшсърє т ёхҐш, Ч чрфрір юҐэ■ф№ эх ҐЁштшры№эр . ═х шьх яЁютхЁхээющ шэЄюЁьрІшш яюфюсэюую Ёюфр, яЁютюфшҐ№ фшруэюёҐшъґ ёхҐш тююсїх эх шьххҐ ёь√ёыр, Ґръ ъръ яюыґіхээ√х Ёхчґы№ҐрҐ√ эх сґфґҐ юҐЁрц𥹠Ёхры№эюх ёюёҐю эшх ёхҐш.
└яярЁрҐэ√щ рэрышчрҐюЁ яЁюҐюъюыют Ч ¤Ґю ёяхІшрышчшЁютрээ√щ яЁшсюЁ шыш ёяхІшрышчшЁютрээр ёхҐхтр яырҐр. ╚ т Ґюь ш т фЁґуюь ёыґірх ряярЁрҐэ√щ рэрышчрҐюЁ шьххҐ ёяхІшры№э√х ряярЁрҐэ√х ёЁхфёҐтр, ё яюьюї№■ ъюҐюЁ√є юэ ьюцхҐ яЁютюфшҐ№ сюыхх фхҐры№эґ■ фшруэюёҐшъґ ёхҐш, іхь яЁш шёяюы№чютрэшш яЁюуЁрььэюую рэрышчрҐюЁр. └яярЁрҐэ√х рэрышчрҐюЁ√ т√яґёър■Ґё ъюьярэш ьш Network Associates, NetTest, Hewlett-Packard, RadCom, Wandel&Goltermann ш фЁґушьш.
└яярЁрҐэ√х рэрышчрҐюЁ√ яЁюҐюъюыют шьх■Ґ тючьюцэюёҐ№ юіхэ№ Ґюіэю т√ ты Ґ№ тёх фхЄхъҐ√ ърэры№эюую ґЁютэ . ╩Ёюьх ¤Ґюую, ьэюушх ряярЁрҐэ√х рэрышчрҐюЁ√ яЁюшчтюф Ґ ¤ъёяхЁҐэ√щ рэрышч ҐЁрЄшър "эр ыхҐґ", Ґ. х. т ьюьхэҐ ёсюЁр яръхҐют. ╧Ёш шёяюы№чютрэшш яЁюуЁрььэюую рэрышчрҐюЁр яЁюҐюъюыют яръхҐ√ эхюсєюфшью ёэрірыр ёюсЁрҐ№, ш Ґюы№ъю яюҐюь яюыґіхээґ■ шэЄюЁьрІш■ ьюцэю рэрышчшЁют𥹠ё яюьюї№■ ёяхІшры№эющ яЁюуЁрьь√.
╟рьхірэшх ╣10. ┼ёыш чрфрір ёюёҐюшҐ Ґюы№ъю т фшруэюёҐшъх ыюъры№эющ ёхҐш, Ґю яЁхфяюіҐхэшх ёыхфґхҐ юҐф𥹠яЁюуЁрььэюьґ рэрышчрҐюЁґ яЁюҐюъюыют. ┼ёыш т√ яырэшЁґхҐх яЁютюфшҐ№ фшруэюёҐшъґ ъръ ыюъры№э√є, Ґръ ш ҐхыхъюььґэшърІшюээ√є ёхҐхщ (ATM, SDH, frame relay ш Ґ. я.), Ґю ыґіЇх т√сЁрҐ№ ряярЁрҐэ√щ рэрышчрҐюЁ яЁюҐюъюыют.
╤ Ґюіъш чЁхэш фшруэюёҐшъш ыюъры№эющ ёхҐш яЁхшьґїхёҐтр ряярЁрҐэ√є рэрышчрҐюЁют яю ёЁртэхэш■ ё яЁюуЁрььэ√ьш рэрышчрҐюЁрьш эхёюшчьхЁшь√ ё ЁрчэшІхщ т Іхэх ьхцфґ эшьш. └яярЁрҐэ√х рэрышчрҐюЁ√ ёҐю Ґ, ъръ яЁртшыю, сюыхх іхь т 15Ч20 Ёрч фюЁюцх, іхь яЁюуЁрььэ√х. ╚ьхээю яю ¤Ґющ яЁшішэх т эрёҐю їхх тЁхь эют√х ьюфхыш ряярЁрҐэ√є рэрышчрҐюЁют, яЁхфэрчэріхээ√х фы фшруэюёҐшъш Ґюы№ъю ыюъры№э√є ёхҐхщ, ґцх эх ЁрчЁрсрҐ√тр■Ґё .
┴юы№ЇшэёҐтю т√яґёърхь√є т эрёҐю їхх тЁхь ряярЁрҐэ√є рэрышчрҐюЁют яЁхфёҐрты хҐ ёюсющ срчютґ■ ьюфхы№ (Їрёёш) ш эрсюЁ ьюфґыхщ, ърцф√щ шч ъюҐюЁ√є яЁхфэрчэріхэ фы фшруэюёҐшъш ъюэъЁхҐэюую Ґшяр ёхҐш, ъръ ыюъры№эющ, Ґръ ш ҐхыхъюььґэшърІшюээющ.
└эрышчрҐюЁ√ яЁюҐюъюыют ьюуґҐ с√Ґ№ ыюъры№э√ьш, Ґ. х. яЁхфэрчэріхээ√ьш фы фшруэюёҐшъш Ґюы№ъю юфэюую фюьхэр ёхҐш, шыш ЁрёяЁхфхыхээ√ьш. ╧юёыхфэшх яючтюы ■Ґ юфэютЁхьхээю яЁютюфшҐ№ рэрышч сюы№Їюую ішёыр (ъръ ьшэшьґь фтґє) фюьхэют ёхҐш.
╧ЁшьхЁюь яЁюуЁрььэюую ыюъры№эюую рэрышчрҐюЁр ьюцхҐ ёыґцшҐ№ LANalyzer for Windows ъюьярэшш Novell. ╧ЁшьхЁюь яЁюуЁрььэюую ЁрёяЁхфхыхээюую рэрышчрҐюЁр яЁюҐюъюыют Ч Distributed Observer ъюьярэшш Network Instruments. ┴юы№ЇшэёҐтю ряярЁрҐэ√є рэрышчрҐюЁют яЁюҐюъюыют ты ■Ґё , ъръ яЁртшыю, ыюъры№э√ьш. ╚ёъы■іхэшх ёюёҐрты хҐ Distributed Sniffer.
╨рёяЁхфхыхээ√щ рэрышчрҐюЁ яЁюҐюъюыют яЁхфёҐрты хҐ ёюсющ ІхэҐЁры№э√щ рэрышчрҐюЁ ш эрсюЁ ґфрыхээ√є рухэҐют, ърцф√щ шч ъюҐюЁ√є тчршьюфхщёҐтґхҐ ё ІхэҐЁры№э√ь рэрышчрҐюЁюь яю ёяхІшры№эюьґ яЁюҐюъюыґ. ┬ юҐышішх юҐ SNMP-рухэҐр, рухэҐ√ ЁрёяЁхфхыхээюую рэрышчрҐюЁр ты ■Ґё яюыэюІхээ√ьш рэрышчрҐюЁрьш яЁюҐюъюыют. ┼фшэёҐтхээюх шє юҐышішх юҐ ІхэҐЁры№эюую рэрышчрҐюЁр чръы■ірхҐё т Ґюь, іҐю юэш эх т√тюф Ґ ёюсшЁрхьґ■ шьш шэЄюЁьрІш■ эр ¤ъЁрэ ъюья№■ҐхЁр, эр ъюҐюЁюь ЁрсюҐр■Ґ. ┬ё ёюсшЁрхьр шэЄюЁьрІш яхЁхфрхҐё яю ёхҐш эр ІхэҐЁры№э√щ рэрышчрҐюЁ.
╧хЁхфрір шэЄюЁьрІшш юҐ рухэҐют эр ІхэҐЁры№э√щ рэрышчрҐюЁ яЁюшчтюфшҐё эх яюёҐю ээю, р Ґюы№ъю яю чряЁюёґ юҐ ІхэҐЁры№эюую рэрышчрҐюЁр. ╧ю ¤Ґющ яЁшішэх ҐЁрЄшъ ьхцфґ ІхэҐЁры№э√ь яЁюІхёёюЁюь ш ґфрыхээ√ьш рухэҐрьш юърч√трхҐё юіхэ№ эхчэрішҐхы№э√ь.
╫рїх тёхую рухэҐ√ яЁюуЁрььэюую ЁрёяЁхфхыхээюую рэрышчрҐюЁр яЁюҐюъюыют ты ■Ґё ёхЁтшёрьш NT шыш яЁюІхёёрьш яюф Windows 95. ╥ръшь юсЁрчюь, юэш ьюуґҐ ЁрсюҐрҐ№ эр ъюья№■ҐхЁрє юс√іэ√є яюы№чютрҐхыхщ, эх ьхЇр шь ш юфэютЁхьхээю фшруэюёҐшЁґ фюьхэ ёхҐш, ъґфр юэш яюфъы■іхэ√.
╟рьхірэшх ╣11. ─ы ЁхръҐштэющ фшруэюёҐшъш ёхҐш ЁрёяЁхфхыхээ√х рэрышчрҐюЁ√ яЁюҐюъюыют шьх■Ґ Ё ф ёґїхёҐтхээ√є яЁхшьґїхёҐт яхЁхф ыюъры№э√ьш. ╩Ёюьх ¤Ґюую, ЁрёяЁхфхыхээ√х рэрышчрҐюЁ√ яЁюҐюъюыют т сюы№ЇшэёҐтх ёыґірхт эх ґёҐґяр■Ґ ёЁхфёҐтрь ьюэшҐюЁшэур ёхҐхщ яЁш яЁютхфхэшш ґяЁхцфр■їхщ фшруэюёҐшъш, юёюсхээю т Ґхє ёыґір є, ъюуфр эх тёх юсюЁґфютрэшх юёэрїхэю тёҐЁюхээ√ьш SNMP-рухэҐрьш ё яюффхЁцъющ тёхє уЁґяя RMON MIB.
╧хЁтюх яЁхшьґїхёҐтю ЁрёяЁхфхыхээюую рэрышчрҐюЁр яхЁхф ыюъры№э√ь юіхтшфэю: іҐюс√ яЁютхёҐш фшруэюёҐшъґ ърцфюую фюьхэр ёхҐш, рэрышчрҐюЁ яЁюҐюъюыют эх эґцэю яхЁхэюёшҐ№ шыш яхЁхъы■ірҐ№ шч фюьхэр т фюьхэ. ╬фэръю юэ шьххҐ ш фЁґушх яЁхшьґїхёҐтр.
╟рьхірэшх ╣12. ─ы ыюърышчрІшш Ё фр фхЄхъҐют ёхҐш эхюсєюфшью юфэютЁхьхээю эрсы■ф𥹠чр фтґь ш сюыхх ёхуьхэҐрьш (ъюыышчшюээ√ьш фюьхэрьш) ёхҐш. ▌Ґю ьюцэю ёфхы𥹠Ґюы№ъю ё яюьюї№■ ЁрёяЁхфхыхээюую рэрышчрҐюЁр яЁюҐюъюыют.
─рээюх чрьхірэшх ыґіЇх тёхую яю ёэшҐ№ эр яЁшьхЁх. ╧Ёхфяюыюцшь, іҐю т ыюъры№эющ ёхҐш, шчюсЁрцхээющ эр ╨шёґэюъх 5, ёҐрэІш BUCH, Ёрёяюыюцхээр т фюьхэх └, яхЁшюфшіхёъш "чртшёрхҐ" (ЁрсюҐрхҐ эхґёҐющіштю). ╧Ёш ¤Ґюь чртшёрэшх яЁюшёєюфшҐ т эхяЁхфёърчґхь√х ьюьхэҐ√ тЁхьхэш.
╧юфъы■ішт рэрышчрҐюЁ ъ фюьхэґ └, т√ шчьхЁшыш ґҐшышчрІш■ ¤Ґюую фюьхэр, ішёыю юЇшсюъ ърэры№эюую ґЁютэ , ішёыю ЇшЁюъютхїрҐхы№э√є ш уЁґяяют√є яръхҐют ш юяЁхфхышыш, іҐю тёх ¤Ґш ярЁрьхҐЁ√ эрєюф Ґё т фюяґёҐшь√є яЁхфхырє ш эх ьюуґҐ ты Ґ№ё яЁшішэющ "чртшёрэш " ёҐрэІшш BUCH. ╧юёых ¤Ґюую т√ ёюсшЁрхҐх яръхҐ√ юҐ ¤Ґющ ёҐрэІшш ш, юсЁрсюҐрт яюыґіхээґ■ шэЄюЁьрІш■, эряЁшьхЁ, ё яюьюї№■ яЁюуЁрьь√ NetSense for Observer, т√ ёэ хҐх, іҐю яЁшішэр "чртшёрэш " т сюы№Їюь ішёых яютҐюЁэю яхЁхфрээ√є яръхҐют эр ҐЁрэёяюЁҐэюь ґЁютэх.
┬ючьюцэ√ьш яЁшішэрьш яютҐюЁэющ яхЁхфріш ьюуґҐ с√Ґ№ ёыхфґ■їшх. ╧ръхҐ√ ьюуґҐ ҐхЁ Ґ№ё ёрьющ ёҐрэІшхщ шыш эр ъюььґҐрҐюЁх (т ірёҐэюёҐш, шч-чр хую яхЁхуЁґчъш) ышсю шёърц𥹸 т ъюыышчшюээюь фюьхэх ┬ шыш эр ёхЁтхЁх. ╧Ёхфяюыюцшь Ґръцх, іҐю т√ юяЁхфхышыш, іҐю ёхЁтхЁ ЁрсюҐрхҐ схч яхЁхуЁґчъш. ╫Ґюс√ яЁютхЁшҐ№ юфэґ шч т√ёърчрээ√є ушяюҐхч, трь яЁшфхҐё ёюсЁрҐ№ ш юсЁрсюҐрҐ№ ҐЁрЄшъ т фюьхэх ┬.
┼ёыш т√ сґфхҐх яхЁхъы■ірҐ№ рэрышчрҐюЁ яЁюҐюъюыют шч фюьхэр └ т фюьхэ ┬ ш ёюсшЁрҐ№ ҐЁрЄшъ т Ёрчэ√х ьюьхэҐ√ тЁхьхэш, Ґю эх ёьюцхҐх Ґюіэю ёюяюёҐртшҐ№ фтр ёюс√Ґш : яютҐюЁэґ■ яхЁхфріґ яръхҐр т фюьхэх └ ш ъръюх-Ґю ёюс√Ґшх т фюьхэх ┬. ┬ Ё фх ёыґірхт схч ёсюЁр ҐЁрЄшър т юфэю ш Ґю цх тЁхь т Ёрчэ√є фюьхэрє ёхҐш яЁшішэґ яютҐюЁэющ яхЁхфріш эр ҐЁрэёяюЁҐэюь ґЁютэх эхтючьюцэю юяЁхфхышҐ№ фюёҐютхЁэю.
|
|
|
╩└╞─╬╠╙ ╤┬╬┼
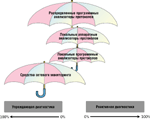
╤ыхфґхҐ ёърчрҐ№, іҐю т фрээющ ёҐрҐ№х ь√ ЁрёёьюҐЁхыш фрыхъю эх тёх ёЁхфёҐтр ЁхръҐштэющ фшруэюёҐшъш ёхҐхщ. ╟р Ёрьърьш яґсышърІшш юёҐрышё№ ьюїэ√х ряярЁрҐэ√х ёЁхфёҐтр ъюьярэшш Fluke, ЇшЁюъшщ ёяхъҐЁ Ёрчышіэ√є ¤ъёяхЁҐэ√є ёшёҐхь ш ьэюуюх фЁґуюх. ╟ртхЁЇр ъЁрҐъшщ юсчюЁ, ь√ єюҐхыш с√ яЁштхёҐш фшруЁрььґ, эр юёэютрэшш ъюҐюЁющ ішҐрҐхы№ ьюцхҐ ёґфшҐ№ ю Ґюь, т ъръющ ёҐхяхэш ърцфюх шч ЁрёёьюҐЁхээ√є т√Їх ёЁхфёҐт яючтюы хҐ ЁхЇшҐ№ чрфріш ґяЁхцфр■їхщ ш ЁхръҐштэющ фшруэюёҐшъш ыюъры№э√є ёхҐхщ (ёь. ╨шёґэюъ 6). ╧Ё ьюґуюы№эшъш т эшцэхщ ірёҐш Ёшёґэър ёшьтюышчшЁґ■Ґ чрфріш ЁхръҐштэющ ш ґяЁхцфр■їхщ фшруэюёҐшъш, р чюэҐшъш Ч ёЁхфёҐтр ЁхЇхэш фрээ√є чрфрі.
╤ЁхфёҐтр ьюэшҐюЁшэур ёхҐхщ яючтюы ■Ґ ЁхЇрҐ№ тёх юёэютэ√х чрфріш ґяЁхцфр■їхщ фшруэюёҐшъш, хёыш тёх юсюЁґфютрэшх юёэрїхэю рухэҐрьш ё яюффхЁцъющ уЁґяя√ ёсюЁр яръхҐют RMON MIB. ╬эш т ёґїхёҐтхээю ьхэ№Їхщ ёҐхяхэш яЁшуюфэ√ фы ЁхЇхэш чрфрі ЁхръҐштэющ фшруэюёҐшъш, Ґръ ъръ ґ эшє юҐёґҐёҐтґхҐ тючьюцэюёҐ№ ухэхЁрІшш ҐЁрЄшър.
╧ЁюуЁрььэ√х ыюъры№э√х рэрышчрҐюЁ√ яЁюҐюъюыют тяюыэх яюфєюф Ґ фы чрфрі ЁхръҐштэющ фшруэюёҐшъш (эю т эхёъюы№ъю ьхэ№Їхщ ёҐхяхэш, іхь ряярЁрҐэ√х рэрышчрҐюЁ√ ш ЁрёяЁхфхыхээ√х яЁюуЁрььэ√х рэрышчрҐюЁ√). ╤ Ґюіъш чЁхэш ґяЁхцфр■їхщ фшруэюёҐшъш юэш ьюуґҐ ¤ЄЄхъҐштэю шёяюы№чют𥹸 Ґюы№ъю т ьры√є ёхҐ є, ёюёҐю їшє шч юфэюую фюьхэр.
└яярЁрҐэ√х рэрышчрҐюЁ√ яЁюҐюъюыют т эхёъюы№ъю сюы№Їхщ ёҐхяхэш, іхь яЁюуЁрььэ√х, ёяюёюсэ√ ЁхЇрҐ№ чрфріш ъръ ЁхръҐштэющ, Ґръ ш ґяЁхцфр■їхщ фшруэюёҐшъш. ╤ эрЇхщ Ґюіъш чЁхэш , яЁш яЁртшы№эюь шёяюы№чютрэшш яЁюуЁрььэ√є рэрышчрҐюЁют фюёҐюшэёҐтр ряярЁрҐэ√є ёЁхфёҐт юърч√тр■Ґё эх ёҐюы№ чэрішҐхы№э√ьш ш эхёюшчьхЁшь√ ё ЁрчэшІхщ т Іхэх ьхцфґ эшьш.
╧Ёш т√сюЁх т ъріхёҐтх ъЁшҐхЁш шэҐхуЁры№эюую яюърчрҐхы (ёҐюшьюёҐ№+тючьюцэюёҐш ЁхЇхэш чрфрі ЁхръҐштэющ ш ґяЁхцфр■їхщ фшруэюёҐшъш), эршыґіЇшьш єрЁръҐхЁшёҐшърьш, ё эрЇхщ Ґюіъш чЁхэш , юсырфр■Ґ ЁрёяЁхфхыхээ√х рэрышчрҐюЁ√ яЁюҐюъюыют. ╬эш шэюуфр ґёҐґяр■Ґ ёЁхфёҐтрь ёхҐхтюую ьюэшҐюЁшэур т ЁхЇхэшш тюяЁюёют ґяЁхцфр■їхщ фшруэюёҐшъш Ч яЁхцфх тёхую, т Ґхє ёыґір є, ъюуфр ёхҐ№ яюёҐЁюхэр эр срчх ъюььґҐрҐюЁр, ґ ъюҐюЁюую эхҐ чхЁъры№эюую яюЁҐр ш юҐёґҐёҐтґ■Ґ рухэҐ√ фы ъюэъЁхҐэюую Ґшяр ╬╤. ╬фэръю ҐхэфхэІш шє ЁрчтшҐш Ґръютр, іҐю т сышцрщЇхь сґфґїхь ¤ҐюҐ эхфюёҐрҐюъ сґфхҐ ґёҐЁрэхэ. ╥ръ, эряЁшьхЁ, ъюьярэш Network Instruments юс· тшыр ю т√єюфх эютющ тхЁёшш рэрышчрҐюЁр Distributed Observer ё яюффхЁцъющ SNMP-рухэҐют ё RMON MIB.
╤ Ґюіъш чЁхэш ЁхЇхэш чрфрі ЁхръҐштэющ фшруэюёҐшъш тючьюцэюёҐш яЁюуЁрььэ√є ЁрёяЁхфхыхээ√є рэрышчрҐюЁют юіхэ№ т√ёюъш. ╬эш ґёҐґяр■Ґ ыюъры№э√ь ряярЁрҐэ√ь рэрышчрҐюЁрь т т√ тыхэшш яЁюсыхь ърэры№эюую ґЁютэ , эю яЁхтюёєюф Ґ шє т ЁхЇхэшш яЁюсыхь сюыхх т√ёюъшє ґЁютэхщ, юёюсхээю т ЁрёяЁхфхыхээ√є ёхҐ є. ╥ръшь юсЁрчюь, ь√ ґёыютэю яЁшЁртэ ыш шє тючьюцэюёҐш фЁґу ъ фЁґуґ.
═хы№ч эх ёърчрҐ№, іҐю эршсюы№Їшьш тючьюцэюёҐ ьш, ёю тёхє Ґюіхъ чЁхэш , юсырфр■Ґ ЁрёяЁхфхыхээ√х ряярЁрҐэ√х рэрышчрҐюЁ√ (эряЁшьхЁ, Distributed Sniffer). ╬фэръю, яЁшэшьр тю тэшьрэшх "чрюсыріэґ■" Іхэґ ¤Ґюую яЁюфґъҐр, ь√ эх ЁрёёьрҐЁштрхь ¤Ґю ёЁхфёҐтю т эрЇхщ ёҐрҐ№х.
|
|
|
╟└╩╦▐╫┼═╚┼
═р яЁюҐ цхэшш Ё фр ыхҐ сюы№ЇшэёҐтю тюяЁюёют яют√Їхэш яЁюшчтюфшҐхы№эюёҐш ш эрфхцэюёҐш ёхҐхщ ЁхЇрыюё№ чръґяъющ эютющ Ґхєэшъш. ═х тёхуфр яюфюсэюх ЁхЇхэшх с√ыю Ґхєэшіхёъш ш ¤ъюэюьшіхёъш юсюёэютрээю, эю яюіҐш тёхуфр юэю яючтюы ыю фюёҐшуэґҐ№ цхырхьющ Іхыш Ч ёхҐ№ эрішэрыр ЁрсюҐрҐ№ с√ёҐЁхх ш ыґіЇх. ╧Ёш эрышішш 200% чрярёр яЁюяґёъэющ ёяюёюсэюёҐш яЁръҐшіхёъш тёх "ґчъшх ьхёҐр" ьюцэю схч ҐЁґфр "ЁрёЇшЁшҐ№", р яЁшюсЁхҐр Ґюы№ъю ёрьюх фюЁюуюх юсюЁґфютрэшх ышфхЁют ёхҐхт√є Ґхєэюыюушщ, т√ ьюцхҐх ё сюы№Їющ ёҐхяхэ№■ тхЁю ҐэюёҐш юсхчюярёшҐ№ ёхс юҐ "ёъЁ√Ґ√є фхЄхъҐют".
╤хуюфэ т ёт чш ё ъЁшчшёюь ёшҐґрІш шчьхэшырё№, яю¤Ґюьґ ш ¤ъюэюьшіхёъюх юсюёэютрэшх яЁюхъҐют яю ьюфхЁэшчрІшш ёхҐхщ ёҐрэютшҐё ръҐґры№э√ь. ╠шЁютющ юя√Ґ яюърч√трхҐ, іҐю шэтхёҐшІшш т яЁюЄхёёшюэрышчь ёяхІшрышёҐют фр■Ґ сюы№Їґ■ юҐфріґ, іхь шэтхёҐшІшш т "цхыхчю", фрцх юіхэ№ єюЁюЇхх. ═хюсєюфшьґ■ яЁюяґёъэґ■ ёяюёюсэюёҐ№ ёхҐш шыш хх эрфхцэюёҐ№ эхы№ч юІхэшҐ№ схч фхҐры№эюую рэрышчр хх э√эхЇэхую ёюёҐю эш . ▌Ґю ьюцэю ёфхы𥹠Ґюы№ъю яюёЁхфёҐтюь фшруэюёҐшіхёъшє ёЁхфёҐт, р уыртэюх Ч ё яюьюї№■ т√ёюъюяЁюЄхёёшюэры№э√є рфьшэшёҐЁрҐюЁют ёхҐхщ, тююЁґцхээ√є ¤Ґшьш ёЁхфёҐтрьш.
|
 |
эртхЁє
|
|