|
|
|
|
| |
 к выбору публикации к выбору публикации
|
|
|
|
Сергей Юдицкий,
Виктор Подлазов,
Владислав Борисенко |
 |
Если программы в вашей сети стали работать медленнее, то постарайтесь определить, каковы причины этого. Иначе вы можете попасть в неприятную ситуацию, когда после дорогостоящей модернизации сети их работа существенно не улучшится.
Данная статья продолжает серию публикаций по вопросам диагностики и тестирования локальных сетей. В статье "Искусство диагностики локальных сетей" в прошлом номере LAN мы уже рассмотрели вопросы диагностики сети на канальном уровне. Предлагаемая же статья посвящена вопросам выявления "узких мест" в архитектуре сети, а также недостаткам прикладного программного обеспечения (ПО), следствием которых оказывается неэффективное использование пропускной способности сервера и сети.
Как показывает многолетний опыт компании "ПроЛАН" в области оказания услуг по диагностике и тестированию сетей, вопросам локализации "узких мест" сети и особенно вопросам выявления недостатков прикладного ПО администраторы сетей уделяют недостаточно внимания. Утверждения типа "все и так работает, зачем нам какая-то диагностика" приходится слышать нередко. Многие администраторы под диагностикой сети понимают исключительно диагностику кабельной системы. Кроме того, зачастую действия администратора по устранению дефектов и/или улучшению работы сети основываются на интуиции, а не на достоверных данных о том, почему сеть работает плохо.
Мы неоднократно встречались со случаями, когда после жалоб пользователей на медленную работу прикладного ПО по настоянию администратора компания закупала новое дорогостоящее сетевое оборудование. Однако после модификации сети выяснялось, что причина ее плохой работы заключалась вовсе не в недостаточной пропускной способности сетевого оборудования или низкой производительности сервера, а, например, в недостатках самого прикладного ПО или просто в неправильной его настройке.
Тем не менее часто администраторы сетей интуитивно определяют проблему правильно, однако у них нет соответствующих технических средств, и они не знают, как аргументированно доказать свою правоту прикладным программистам или убедить руководство в необходимости закупки новой техники.
Аналогичная ситуация часто возникает, когда прикладное ПО неадекватно работает вследствие дефектов локальной сети. При этом клиенты всю вину возлагают на внедряемое ПО, а программисты не знают, как доказать обратное.
По нашему мнению, в большинстве случаев для выявления недостатков архитектуры сети и прикладного ПО достаточно анализатора сетевых протоколов. В предыдущей статье мы уже рассказали о том, как правильно организовать процесс диагностики сети с помощью анализатора протоколов и какие функции анализатора протоколов особенно важны для эффективной организации процесса диагностики. Здесь заметим только, что этими функциями в полной мере обладает, в частности, программный анализатор протоколов Observer компании Network Instruments. Данную статью мы будем иллюстрировать на примере использования именно этого программного продукта.
|
 |
Что такое "узкое место" сети
Так же, как скорость эскадры определяется скоростью самого тихоходного судна в ее составе, так и пропускная способность всей сети соответствует уровню ее самого низкопроизводительного архитектурного компонента. Такой компонент обычно и называют "узким местом" сети. Им могут быть активное оборудование (коммутатор, концентратор, сервер), программное обеспечение, один или несколько параметров настройки оборудования или программного обеспечения. Как в любой эскадре есть тихоходное судно, так в любой сети есть "узкие места". Однако устранение "узкого места" не всегда целесообразно.
Наличие или отсутствие "узких мест" зависит от того, какое прикладное ПО используется в сети. В общем случае какой-либо архитектурный компонент сети нельзя считать "узким местом" без конкретизации ПО, для которого он таковым является. В одной и той же сети для разных типов прикладного ПО "узкими местами" могут быть разные архитектурные компоненты. Например, если для прикладного ПО на базе Fox Pro наиболее вероятным "узким местом" будет производительность канала связи или дисковой подсистемы сервера, то для прикладного ПО на базе Oracle — производительность процессора сервера.
"Узкие места" условно можно разделить на две категории: скрытые и явные. К явным следует отнести общие сетевые ресурсы с недостаточной пропускной способностью. Так, например, к категории явных "узких мест" можно отнести неадекватную производительность процессора или дисковой подсистемы сервера, недостаточную пропускную способность коммутатора или домена сети.
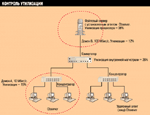
Наличие явных "узких мест" можно иллюстрировать на следующем примере. Если прохождение информации по сети соотнести с прохождением жидкости по системе соединенных труб (см. Рисунок 1), то каждый общий сетевой ресурс можно сравнить с трубой определенного диаметра. Диаметр трубы соответствует пропускной способности ресурса, а степень наполнения трубы жидкостью —утилизации ресурса.
"Узкое место" сети можно сравнить с полностью заполненной трубой (утилизация близка к естественному пределу — 100%), из-за чего остальные трубы оказываются незаполненными.
Таким образом, пропускная способность других труб (ресурсов) используется неэффективно.
Скрытыми "узкими местами" являются такие алгоритмы, процессы или параметры настройки оборудования либо программного обеспечения, из-за которых пропускная способность сети оказывается неадекватно низкой. Так, например, к категории скрытых "узких мест" можно отнести параметры настройки оборудования, вызывающие "широковещательные штормы" (см. Правило №4.1), или параметры настройки прикладного ПО, приводящие к увеличению доли коротких кадров (см. Правило №3.1). К категории скрытых "узких мест" следует отнести и алгоритмы работы прикладного ПО, следствием которых является неэффективное использование пропускной способности сети (см. Правило №5.1).
|
|
|
Недостаточная пропускная способность общего сетевого ресурся
Правило №1.1. Уровень утилизации общих сетевых ресурсов с одинаковой дисциплиной обслуживания заявок в хорошо сбалансированной сети не должен существенно отличаться.
Общими сетевыми ресурсами обычно являются коммутаторы, концентраторы (домены сети), серверы. Утилизация ресурса — это процент используемой пропускной способности. Дисциплина обслуживания заявок — это набор правил, в соответствии с которыми ресурс обрабатывает поступающие заявки на обслуживание.
Для канала связи, например, дисциплина обслуживания выражается в правиле: "Первым пришел, первым обслужен" (FIFO). Как только заявка поступает, она сразу выполняется. Если канал связи свободен, то станция сразу передает кадр; таким образом, при наличии заявки на обслуживание канал связи не простаивает.
Для дисковой подсистемы сервера дисциплина обслуживания заявок другая. С целью минимизации общего времени обслуживания заявки сначала накапливаются, а потом выполняются. В результате этого диск может простаивать даже при наличии некоторого числа заявок.
Если уровни утилизации общих ресурсов существенно отличаются друг от друга, то такую сеть принято называть "плохо сбалансированной по нагрузке". В этом случае необходимо заменить активное оборудование и/или изменить архитектуру сети. Данная процедура называется "выравнивание нагрузки" (load balancing).
Обычно принято считать, что для определения того ресурса, пропускная способность которого сильнее других влияет на время реакции конкретного ПО, надо измерить утилизацию всех общих ресурсов, возникающую при работе этого ПО. Чем выше утилизация ресурса, тем критичнее пропускная способность этого ресурса для времени реакции прикладного ПО. Это верно в случае сравнения ресурсов с одинаковой дисциплиной обслуживания заявок, например для коллизионных доменов сети (collision domain).
Предположим, что ваша сеть имеет архитектуру с компактной магистралью (collapsed backbone), как показано на Рисунке 2. Для того чтобы определить, какой из доменов сети (домен А на 10 Мбит/с или домен В на 100 Мбит/с) в большей степени влияет на время реакции прикладного ПО, загруженность этих доменов надо сравнить между собой. Несмотря на то что сравниваемые ресурсы имеют разную номинальную пропускную способность (10 Мбит/с и 100 Мбит/с), наибольшее влияние на время реакции прикладного ПО оказывает тот домен, значение утилизации которого выше.
Обращаем ваше внимание, что в рассмотренном примере еще нельзя сказать, что тот домен сети, который в большей степени (чем остальные) влияет на работу прикладного ПО, является "узким местом" сети. Найти именно "узкое место" сети можно, только оценив влияние всех общих ресурсов (а не только доменов сети) на работу ПО и определив, какой ресурс влияет в наибольшей степени. Если в рассмотренном примере "узким местом" оказывается, например, дисковая подсистема сервера, то утилизация доменов может быть относительно низкой.
Измерить утилизацию доменов сети особого труда не составляет. Если сетевое оборудование имеет встроенные SNMP-агенты, то такие измерения можно провести с помощью любой программы управления на базе SNMP.
Другой способ измерения утилизации доменов сети основан на использовании анализатора протоколов вместе с удаленными агентами (или зондами). Установив в каждом интересующем вас домене сети удаленный агент, вы сможете одновременно измерить утилизацию таких доменов (см. Рисунок 2).
Если ресурсы, например сервер и коммутатор, имеют разную дисциплину обслуживания заявок, то сравнивать значение их утилизации и на основании такого сравнения делать выводы о том, какой ресурс в наибольшей степени влияет на время реакции прикладного ПО, не вполне верно.
Примечание. Это не относится к случаям, когда утилизация ресурсов отличается более чем на порядок. Если, например, утилизация процессора сервера составляет 99%, а утилизация канала связи — 2%, то вы можете с полным основанием утверждать, что производительность процессора сервера влияет на работу прикладного ПО в большей степени, чем пропускная способность канала связи. Однако если разница не столь значительна, то категоричные выводы делать нельзя.
Правило №1.2. Чтобы определить, какой общий ресурс является "узким местом" сети, вы должны точно знать, утилизация какого ресурса ближе других к допустимому или к естественному пределу.
Если в процессе измерений вы определили, что утилизация какого-то ресурса близка к естественному пределу (к 100%), то этот ресурс однозначно является "узким местом" сети. Обычно с интерпретацией результатов, в которых утилизация ресурсов близка к естественному пределу, особых проблем не возникает. Намного сложнее интерпретировать результаты, в которых утилизация общих ресурсов различна и далека от естественных пределов.
Допустимый предел утилизации (см. Правило №1.3) обычно меньше естественного (меньше 100%), а его значение зависит от многих условий.
Предположим, что вы измерили утилизацию всех общих ресурсов сети (изображенной на Рисунке 2) и определили, что утилизация домена А составила 19%, утилизация внутренней магистрали коммутатора — 26%, домена B — 12%, процессора сервера — 36%. Позволяют ли полученные данные сделать вывод о том, что "узким местом" является недостаточная производительность процессора сервера? Нет, так как эти ресурсы имеют разную дисциплину обслуживания заявок, и мы изначально не знаем, утилизация какого ресурса ближе других находится к допустимому пределу.
Таким образом, мы подошли к вопросу о том, как определить допустимый предел утилизации ресурса.
Правило №1.3. При эксплуатации сети утилизация ресурсов должна быть не выше допустимых пороговых значений.
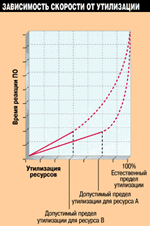
Из теории массового обслуживания известно, что в общем случае скорость выполнения операций в сети гиперболически зависит от утилизации общих ресурсов (см. Рисунок 3). За верхнее допустимое значение обычно принимается утилизация, при которой заканчивается "линейный" участок гиперболы. Однако крутизна кривой и протяженность "линейного" участка для разных типов ресурсов могут быть различны. Это означает, что допустимое значение утилизации (допустимый предел) для разных типов ресурсов различно.
Максимально допустимая утилизация зависит от множества факторов, и прежде всего от типа трафика. В предыдущей статье мы подробно рассмотрели методику определения допустимого предела утилизации домена сети. Аналогичными методами можно найти допустимый предел утилизации коммутатора или маршрутизатора.
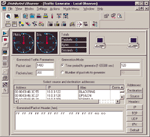
Ряд анализаторов протоколов, например Observer компании Network Instru-
ments, имеют функцию генерации трафика (см. Рисунок 4). Изменяя параметры Packets/sec (число пакетов в секунду) и Packet size (размер пакета), вы можете варьировать интенсивность генерируемого анализатором трафика, а изменяя параметр destination (приемник) — направление генерируемого трафика. Зависимость между утилизацией ресурса и временем реакции можно оценить, измеряя время реакции прикладного ПО на фоне увеличения генерируемой нагрузки. Зная эту зависимость, вы можете определить, при какой утилизации ресурса заканчивается "линейный" участок гиперболы или какой утилизации ресурса соответствует требуемое время реакции прикладного ПО (например, 2 с, см. врезку "Какая сеть хороша?"). Это значение утилизации и будет являться допустимым пределом утилизации ресурса.
Определить допустимый предел утилизации различных компонентов сервера намного сложнее (см. раздел узкое место — "Производительность сервера").
Правило №1.4. Ликвидация "узкого места" при определенных условиях может привести не к увеличению, а к уменьшению пропускной способности сети.
Как мы уже говорили выше, ликвидация "узкого места" не всегда достигает цели. Признаком целесообразности устранения "узкого места" является наличие в сети только одного "узкого места", и то только в том случае, если "расширение" "узкого места" позволит ускорить работу прикладного ПО (см. Правило №6.1).
При наличии в сети нескольких ресурсов, утилизация которых близка к допустимому пределу, устранив одно "узкое место", вы создадите условия для проявления другого. При этом нет никакой гарантии того, что пропускная способность сети после устранения такого "узкого места" увеличится. Иногда она может даже уменьшиться.
Рассмотрим хрестоматийный пример того, как при ликвидации "узкого места" пропускная способность сети уменьшается. Предположим, что в сети Ethernet формально "узким местом" для используемого ПО является канал связи, но пропускная способность дисковой подсистемы и канала связи приблизительно равны. Другими словами, канал связи как бы заслоняет собой другое потенциальное "узкое место" — дисковую подсистему сервера.
Сеть развивается, число пользователей увеличивается, и вы, например, решили, не меняя сервера, заменить сеть Ethernet на сеть Fast Ethernet. В этом случае канал связи перестает быть "узким местом", но не дисковая подсистема сервера. Нагрузка на дисковую подсистему увеличится, и, следовательно, ее утилизация возрастет. Если при этом крутизна гиперболической зависимости времени реакции от утилизации дисковой подсистемы (см. Правило №1.3) больше, чем для канала связи, то скорость выполнения операций в сети уменьшится.
В материалах компании Ziff Davis, разработчика тестов NetBench и ServerBench, приводится интересное образное объяснение этого феномена. Представьте себе вежливого продавца, который обслуживает очередь покупателей с максимальной для себя быстротой. В магазин заходит новая группа покупателей. Поскольку продавец уже не может работать быстрее, он начинает отвлекаться, нервничать и объяснять покупателям, что не сможет их быстро обслужить. В результате он начинает работать медленнее, чем ранее.
|
|
|
Производительность сервера
Особого внимания заслуживает вопрос о том, как проверить тот факт, что "узким местом" сети является недостаточная производительность сервера.
Очевидно, что перегруженный сервер замедляет работу сети. Однако ответ на вопрос о том, каковы признаки перегрузки сервера, совершенно не очевиден. Многие не совсем правильно полагают, что таким признаком однозначно можно считать высокую утилизацию процессора сервера.
Сервер — это сложная система, в состав которой кроме процессора входит множество различных компонентов: системная шина, дисковая подсистема, оперативная память и др. Каждый из этих компонентов имеет свою дисциплину обслуживания заявок, и каждый теоретически может быть "узким местом" сети.
Утилизация процессора сервера характеризует степень загрузки только одного компонента — процессора. Мы неоднократно наблюдали картину, когда при уровне утилизации процессора менее 50% сервер работал с большими перегрузками. Чаще всего это бывает в том случае, когда сервер с невысокой пропускной способностью дисковой подсистемы обрабатывает большие файлы.
Признаком перегрузки других компонентов сервера могут быть такие показатели, как число "грязных" кэш-буферов, число отложенных запросов к диску, число "попаданий в кэш" и многие другие. Эти показатели, как правило, не выражаются в процентах, что существенно осложняет процесс определения "узкого места". Более того, методика определения "узкого места" сильно зависит от типа сетевой ОС, в частности она различна для сервера с Windows NT и с NetWare.
В рамках данной статьи, ввиду объемности и сложности материала, мы не можем рассказать о том, как определить, какой конкретно компонент сервера является "узким местом". Эта задача решается только с использованием метода стрессового тестирования сети, о котором мы планируем рассказать в последующих публикациях. Тем, кого эта проблема интересует, мы рекомендуем прочесть книгу Расса Блейка "Optimizing Windows NT", которая входит в состав "Windows NT Resource Kit", издаваемого Microsoft Press.
В данной статье мы ограничимся рассмотрением двух правил, знание которых поможет вам установить, что сервер работает с перегрузкой, т. е. что утилизация какого-то компонента сервера выше средней или близка к допустимому пределу.
Правило №2.1. Признаком перегрузки сервера NetWare является специальный пакет протокола NCP, который сервер высылает в ответ на повторный запрос от рабочей станции, если предыдущий запрос от той же рабочей станции еще обрабатывается сервером. Такие пакеты обычно называются Delay packet, Server busy replies или Being processed packet.
Отправив по протоколу NCP запрос к серверу NetWare на выполнение какой-то операции, рабочая станция включает тайм-аут и ждет от сервера ответа о выполнении этой операции. Если ответ не приходит в течение фиксированного времени (тайм-аута), то станция повторяет запрос для проверки того, что он не был потерян при передаче по сети. Получив повторный запрос от рабочей станции, сервер отвечает ей специальным пакетом, который, как мы говорили, называется Delay packet, Server busy replies или Being processed packet. Сервер как бы просит станцию не волноваться: "Запрос получен, но я не могу на него сейчас ответить". Получив пакет, рабочая станция обнуляет свой тайм-аут и продолжает ждать ответа от сервера. Наличие таких пакетов в сети свидетельствует о том, что сервер не успевает обрабатывать запросы от рабочих станций. Чем больше в сети подобных пакетов, тем сильнее перегружен сервер. Подробнее об этом можно прочесть в книге Лауры А. Чаппел и Дэна Е. Хейкса "Анализатор локальных сетей NetWare", изданной Novell PRESS.
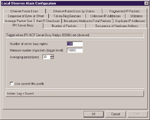
Обычно анализаторы сетевых протоколов имеют специальный входной фильтр, позволяющий фиксировать наличие и определять число таких пакетов в сети (см. Рисунок 5). Установив значение параметров Number of server busy replies ("Число ответов сервера о том, что он занят") и Averaging period ("Период усреднения"), анализатор протоколов информирует вас, когда число ответов сервера о перегрузке за заданный промежуток времени превысит установленное значение.
Ответы сервера о перегрузке всегда адресованы конкретной станции, поэтому анализатор протоколов позволяет легко определить, какое именно прикладное ПО и какая именно рабочая станция перегружают сервер.
Правило №2.2. Признаком перегрузки сервера является возросшее время ответа сервера на запросы рабочих станций.
Если прикладное ПО не использует протокол NCP в качестве транспортного средства, то перегрузку сервера можно определить по длительности реакции сервера на запросы от рабочих станций.
Время реакции сервера автоматически определяется некоторыми анализаторами протоколов. В Observer время реакции каждого узла сети входит в состав статистики по каждой паре станций и называется latency (см. Рисунок 6).
|
|
|
Большое число коротких кадров
Как мы уже говорили выше, скрытым "узким местом" может быть не только недостаточная пропускная способность ресурсов сети, но и параметры настройки оборудования или ПО.
Правило №3.1. Пропускная способность сети существенно зависит от типа сетевого трафика. Чем больше число коротких кадров, тем менее эффективно используется пропускная способность сети.
Пропускная способность любого сетевого ресурса зависит от типа сетевого трафика. Так, пропускная способность файлового сервера зависит от размера файлов, которые он обрабатывает. Чем чаще файлы помещаются в кэш-память сервера, тем выше его пропускная способность. Пропускная способность маршрутизатора зависит от типа маршрутизируемого протокола.
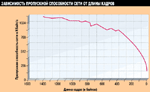
Пропускная способность канала связи (коммутаторов и концентраторов) существенно зависит от размера кадров. Чем большую долю в общем числе кадров занимают короткие кадры, тем менее эффективно используется пропускная способность канала связи. На Рисунке 7 пропускная способность сети Ethernet показана в зависимости от длины кадров (она была измерена утилитой perform3 компании Novell). Несмотря на то что вид кривой зависит от используемых сетевых адаптеров, снижение пропускной способности сети при уменьшении размера кадров характерно для всех типов сетей (Ethernet, Fast Ethernet, Token Ring, FDDI).
В этой связи измерение доли кадров конкретной длины приобретает большее значение. Такое измерение можно провести с помощью специальных утилит (например, psd.exe компании Novell) или анализатора протоколов. Анализатор Observer автоматически строит распределение кадров по длинам. Результат его работы показан на Рисунке 8.
|
|
|
Рост числа широковещательных пакетов
Правило №4.1. В соответствии с отраслевым стандартом де-факто число широковещательных и многоадресных кадров в сети не должно превышать 8—10% от общего числа кадров (Robert W. Buchanan, Jr, "The Art of Testing Network Systems"; Wiley Computer Publishing).
Широковещательный кадр — это кадр, адресованный всем станциям в домене сети. Многоадресный кадр — это кадр, адресованный группе станций в домене сети. Поскольку широковещательный кадр адресован всем станциям, то, получив его, станции должны прервать свою работу и обработать такой кадр. Это замедляет работу всей сети.
Если отношение числа широковещательных кадров к общему числу кадров больше 10%, то такой эффект называется "широковещательным штормом".
Широковещательный шторм может быть следствием дефектов оборудования или неправильной настройки параметров активного оборудования. Чаще всего это явление наблюдается в распределенных сетях NetWare, построенных на основе коммутаторов, или когда данные между сегментами или доменами сети могут передаваться более чем по одному потенциальному пути. Если один из коммутаторов такой сети не поддерживает протокол Spanning Tree (обычно IEEE 802.1d) или последний неправильно настроен либо сбоит, то в сети начинается неуправляемая циркуляция широковещательных кадров.
Выявление "широковещательного шторма" является не столь тривиальной задачей, как это может показаться на первый взгляд. Для его обнаружения недостаточно взять общее число широковещательных кадров и поделить его на общее число кадров, прошедших по сети.
Для этого вы должны определить: какую долю составляют широковещательные кадры в каждый интервал времени (например, за одну минуту) и какова при этом утилизация канала связи. Если, например, за одну минуту по сети прошло 4 кадра, а 2 из них были широковещательными, то это еще не значит, что вы наблюдаете "широковещательный шторм".
Данная задача хорошо решена в анализаторе протоколов Observer (см. Рисунок 9). Совмещенный график отображает долю (в процентах) широковещательных и многоадресных кадров как функцию утилизации канала связи. При этом цветом выделяется степень загрузки сети. Если цвет линий желтый, то утилизация сети менее установленного порога (обычно 5%). При такой утилизации доля широковещательных и групповых кадров особого интереса не представляет. При зеленом цвете линий утилизация сети высокая, но доля широковещательных и групповых кадров менее установленного порога (по умолчанию 10%). Если же цвет линий красный, то это означает, что утилизация канала связи и доля широковещательных и многоадресных кадров выше установленного порога. Это признак "широковещательного шторма".
|
|
|
Неэффективные алгоритмы прикладного ПО
Под неэффективными алгоритмами работы прикладного ПО мы будем понимать такие алгоритмы, применение которых не позволяет максимально полно использовать пропускную способность ресурсов сети.
Обычно работа прикладного ПО состоит в выполнении инициируемых пользователем операций. Примерами таких операций могут быть поиск записи в базе данных, выписка счета или накладной, проводка платежного поручения и т. п. Для каждого типа прикладного ПО всегда можно выделить одну или несколько наиболее часто используемых операций, время выполнения которых особенно критично для пользователей. Говоря об эффективности прикладного ПО, мы имеем в виду эффективность выполнения в сети именно таких операций, которые в дальнейшем будем называть типовыми задачами.
Чтобы определить, насколько эффективно используются ресурсы сети, мы рекомендуем провести несколько экспериментов с типовыми задачами. Суть экспериментов заключается в одновременном запуске типовых задач на N (N = 1,2,3...) рабочих станциях. Цель экспериментов — измерить время выполнения типовой задачи при различном числе станций и соответствующие значения утилизации сетевых ресурсов (канала связи, процессора сервера, процессоров рабочих станций и т. д.).
Вопрос о том, как реализовать подобные эксперименты, т. е. как синхронизировать запуск задачи на разных станциях, как фиксировать время выполнения задачи, как учитывать различное быстродействие рабочих станций и т. п., решается в каждом случае по-разному с учетом специфики сети и прикладного ПО. Для проведения грубых экспериментов в первом приближении исследуемую типовую задачу можно выполнять циклически (многократно, для увеличения общего времени выполнения), с внешней регистрацией времени выполнения, запуском задачи на близко расположенных станциях (для визуальной синхронизации запуска) и выбором для каждого эксперимента станций примерно равного быстродействия.
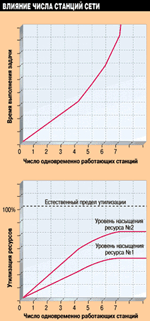
Обычно при малом числе одновременно работающих станций время выполнения задачи и утилизация сетевых ресурсов растут линейно с ростом числа станций (см. Рисунок 10). Однако при превышении некоторого числа станций время выполнения задачи начинает расти быстрее, чем линейно, а утилизация сетевых ресурсов — медленнее, чем линейно, после чего происходит насыщение графиков.
Если уровень насыщения утилизации какого-то ресурса оказывается близким к естественному пределу пропускной способности этого ресурса, то типовая задача использует данный ресурс эффективно. Чем ниже уровень насыщения (дальше от естественного предела пропускной способности), тем менее эффективно используется ресурс.
Правило №5.1. Насыщение утилизации всех сетевых ресурсов на уровне существенно ниже естественного предела их пропускной способности служит признаком того, что "узким местом" являются неэффективные алгоритмы работы прикладного ПО.
Если утилизация какого-то ресурса оказывается близка к естественному пределу его пропускной способности, то именно данный ресурс представляет собой "узкое место" для конкретной типовой задачи.
|
|
|
Какое "узкое место" следует устранять в первую очередь
Если вы определили, какой именно ресурс является "узким местом" вашей сети, то затем вы должны установить, как устранение этого "узкого места" повлияет на время реакции ПО.
Правило №6.1. Чем больше доля времени, приходящаяся на конкретный сетевой ресурс при выполнении типовой задачи, тем большее ускорение в решении задачи будет достигнуто при увеличении пропускной способности этого ресурса. В первую очередь надо увеличивать пропускную способность того ресурса, на который приходится наибольшая доля времени выполнения типовой задачи.
Для этого вы должны знать, какая доля времени приходится на каждый из ресурсов. Основными ресурсами, как правило, можно считать канал связи, сервер и рабочую станцию.
Приходящуюся на канал связи долю времени (Дканала) можно установить, измерив утилизацию канала связи при одной работающей станции. Если в сети в момент измерения не будет других пользователей, то долю канала можно вычислить по следующей формуле:
Дканала = Утилизация канала/100
Чтобы определить, какая доля времени приходится на сервер, и при этом учесть вклад всех компонентов сервера (дисковой подсистемы, ОЗУ и др.), время выполнения типовой задачи следует измерить при одной и двух одновременно работающих станциях. В общем случае долю времени, которая приходится на сервер (Дсервера), можно вычислить по формуле:
Дсервера = ј(2*(T1/T2–1)–Дканала),
где Т1 и Т2 — время выполнения задачи при одной и двух одновременно работающих станциях соответственно.
Если считать, что основная задержка связана с процессором сервера, а вносимой остальными компонентами сервера задержкой можно пренебречь, то долю сервера можно принять пропорциональной утилизации процессора сервера. Доля сервера в этом случае будет определяться следующим образом:
Дсервера = Утилизация процессора сервера/100
Долю времени, которая приходится на рабочую станцию (Дстанции) можно оценить, как:
Дстанции = (1 – Дканала – Дсервера)1/2
Зная приходящуюся на каждый из основных общих ресурсов сети долю времени, вы легко сможете определить, производительность какого ресурса вам следует увеличить в первую очередь.
Если вы определили, предположим, что передача данных по каналу связи занимает 10% времени решения задачи (Дканала = 0,1), выполнение операций на сервере — 5% (Дсервера = 0,05), а на рабочей станции — 85% (Дстанции = 0,85), то какой бы высокой производительностью ни обладал ваш новый сервер, вы не получите ускорения в решении задачи более чем на 5%. Аналогично, если ваша сеть будет работать со скоростью света, вы все равно не получите ускорения в решении задачи более чем на 10%. В таких случаях модифицировать прежде всего следует рабочие станции (или алгоритмы работы прикладного ПО).
 |
|
|
Два подхода к оценке качества сети
Какая сеть хороша?
При оценке качества сети возможны два подхода: с точки зрения пользователя и с точки зрения администратора сети. С точки зрения пользователя, основными критериями качества сети являются время реакции и надежность работы прикладного ПО.
Как показали исследования, проведенные группой американских психологов, время реакции прикладной системы для пользователей, работающих в диалоговом режиме, не должно превышать 2 секунды (William Stallings, "SNMP, SNMPv2, and CMIP. The Practical Guide to Network-Management Standards", Addison-Wesley Publishing Company). Если время реакции оказывается большим, то пользователи чувствуют себя некомфортно, быстро устают, часто делают ошибки, производительность их труда становится низкой.
Кроме того, что сеть должна работать быстро, она должна работать еще и надежно. Если в процессе эксплуатации сети пользователи периодически сталкиваются со случаями, когда информация в сети искажается или исчезает, они также чувствуют себя некомфортно и все свои ошибки склонны "сваливать" на сеть.
Администратор оценивает качество сети по наблюдаемым параметрам ее работы. Критичные для времени реакции прикладного ПО параметры не должны превышать допустимых пределов. Такими параметрами, в частности, являются: число ошибок при передаче данных, число коллизий, число широковещательных и многоадресных пакетов, утилизация канала связи и сервера. Допустимые пределы параметров регламентируются отраслевыми стандартами де-факто. О части из них (таких, как число и тип ошибок при передаче данных, утилизация канала связи, число и тип коллизий и др.) мы уже рассказали в предыдущей статье. С некоторыми другими параметрами мы познакомимся в данной статье. При этом следует помнить, что несмотря на то, что подобные стандарты создавались именно с целью минимизации времени реакции прикладного ПО и увеличения надежности работы сети, ни один стандарт не может учесть все особенности конкретной сети и конкретного прикладного ПО.
Вывод. Хорошая сеть — это такая сеть, которая, с одной стороны, обеспечивает требуемое время реакции прикладного ПО, и, с другой стороны, та, параметры работы которой не выходят за рамки отраслевых стандартов.
|
 |
наверх
|
|