|
|
|
|
| |
 к выбору публикации к выбору публикации
|
|
|
|
Сергей Юдицкий,
Владислав Борисенко,
Петр Адаскин |
 |
Если возможности имеющихся в вашем распоряжении диагностических средств не позволяют определить причину сбоев в сети, то следует воспользоваться методом активного тестирования сети.
Если пользователи сети жалуются, что приложения работают медленно, периодически сбоят, а одну и ту же работу приходится выполнять по несколько раз, то это означает, что пора проводить тестирование. Главный вопрос, на который предстоит ответить администратору сети, состоит в следующем: "В чем причина медленной работы пользовательских приложений — в "узких местах" или дефектах сети, либо же в неправильной настройке или недостатках самих пользовательских приложений?" (Под термином "сеть" мы будем понимать все компоненты сети в комплексе: пассивное сетевое оборудование — кабель, розетки, панели переключений; активное сетевое оборудование — коммутаторы, маршрутизаторы, а также рабочие станции и серверы сети с установленными на них сетевыми ОС.)
Возможны два подхода к решению данной задачи. Первый подход — "эмпирический", в настоящее время он доминирует в России. В соответствии с этим подходом администраторы сети пытаются решить проблему, руководствуясь только интуицией и здравым смыслом. Одни осуществляют замену сетевого оборудования, особо не задумываясь при этом, действительно ли именно оборудование "виновато" в медленной работе приложений. Другие начинают производить различные изменения в топологии или архитектуре сети, устанавливают или убирают поддержку различных протоколов, меняют форматы кадров, изменяют параметры настройки прикладного ПО, оборудования или ОС. Третьи просто уходят от проблемы, перекладывая решение задачи на компанию, которая устанавливала сеть или прикладное ПО. Однако в общем случае ни один из этих способов не гарантирует решения проблемы.
Второй подход основан на поиске причин медленной работы приложений с помощью различных диагностических средств. Данный подход пока не очень распространен в России. И причина этого состоит, вероятно, в том, что "психологически" значительно проще истратить несколько тысяч долларов США на новое оборудование, чем на диагностическое средство (особенно программное), и уж тем более на услуги по диагностике сети. В результате диагностические средства для решения конкретных задач используют, как правило, только в тех случаях, когда "эмпирический" подход оказался нерезультативным, и другого выхода просто нет.
И даже когда компания в результате неудач "эмпирической" модернизации сети, казалось бы, должна была осознать необходимость продуманного профессионального подхода к приобретению новых средств, стратегия многих компаний в отношении диагностических средств часто удивляет своей иррациональностью. Вместо выяснения того, какое диагностическое средство для решения какого типа задачи предназначено, многие компании при его выборе руководствуются принципами "как у соседа" или "где дешевле". Так, одни компании выбрасывают десятки тысяч долларов на престижные системы управления сетью. Однако при всех своих достоинствах такие системы оказываются зачастую неэффективными для решения специфических задач диагностики сети, а кроме того, требуют приобретения дополнительных зондов или специализированных приложений, стоимость которых немногим меньше стоимости самой системы управления. Другие же приобретают "игрушечные средства", которые в принципе не предназначены для решения сложных задач и поэтому оказываются малоэффективными.
|
 |
Традиционная методология диагностики сети и ее ограничения
Традиционными средствами диагностики сети являются анализаторы сетевых протоколов и программы на основе SNMP с поддержкой RMON1/RMON2. Для краткости мы будем называть их пассивными средствами диагностики. Методика использования пассивных средств основана на анализе сетевого трафика. Анализируя и декодируя сетевой трафик, эти средства позволяют выявить симптомы медленной работы приложений. Мы достаточно подробно рассмотрели такие симптомы в наших предыдущих статьях (см. статьи по диагностике в предыдущих номерах LAN). Однако чтобы лучше понимать проблематику поиска дефектов и "узких мест" в сети, мы хотели бы все же сказать несколько слов о методологии процесса диагностики сети с помощью пассивных средств.
Поиск дефектов и "узких мест" сети с помощью пассивных средств диагностики можно охарактеризовать как поиск "от противного". Это означает, что о качестве работы сети судят по отсутствию симптомов дефектов. Так, например, как известно, доля искаженных кадров не должна превышать 1% от общего числа кадров. Поэтому вы измеряете, сколько в вашей сети искаженных кадров. Кроме того, число широковещательных и групповых кадров в сети не должно превосходить 8—10% от общего числа кадров, и поэтому вы измеряете, какова их доля в вашей сети. Далее, утилизация канала разделяемой сети Ethernet не должна быть больше ~35%, и поэтому вы измеряете значение этого параметра. Перечень симптомов можно продолжить и далее.
Очевидно, что эффективность метода "от противного" зависит от двух основных факторов.
Фактор №1. Возможности используемого диагностического средства по фиксации симптомов проблем. Чем больше симптомов может выявить диагностическое средство и чем больше компонентов сети им охватывается, тем оно эффективней.
Например, эффективность диагностического средства зависит от того, какие типы ошибок при передаче данных позволяет обнаружить диагностическое средство и все ли кадры оно перехватывает при высокой загруженности сети; от его способности фиксировать сбои в полнодуплексных каналах связи, а также сбои или перегрузку конкретных систем сервера (например, сетевой платы) и рабочих станций, видеть не только искаженные кадры, но и шум в линии связи, определять число повторных передач на транспортном уровне сети, время реакции каждого узла сети, факты перегрузки сервера.
Очевидно, что самая дорогая система на базе SNMP будет бесполезна, если в сети отсутствуют зонды SNMP/RMON или если они контролируют только незначительную часть сети, например только центральный коммутатор. Очевидно также, что анализатор сетевых протоколов не позволит со 100-процентной вероятностью локализовать дефект, если он не способен фиксировать симптомы дефектов на транспортном уровне сети.
Фактор №2. Умение администратора сети правильно интерпретировать получаемую с помощью диагностического средства информацию.
Если диагностическое средство позволяет фиксировать несколько десятков характеристик работы сети, а администратор сети следит только за утилизацией портов коммутатора и долей искаженных кадров, то вряд ли это можно назвать эффективным использованием диагностического средства.
Очевидно, что чем большими возможностями обладает диагностическое средство, тем оно дороже. Стоимость средств для сбора полной информации о работе сети составляет сумму в диапазоне от 15 000 до 25 000 долларов, не считая стоимости экспертной системы. Вывод же о своем умении интерпретировать характеристики работы сети мы предлагаем каждому читателю сделать самостоятельно.
Иметь дорогое многофункциональное диагностическое средство лучше, чем его не иметь. Так же, как "лучше быть здоровым и богатым, чем бедным и больным". Однако, приобретая диагностическое средство, вам следует проанализировать не только его потенциальные возможности, но и то, насколько эффективно оно может быть использовано именно в вашей сети. Например, оно может быть эффективно использовано для работы только с определенным типом оборудования и таким образом потребует замены большей части активного сетевого оборудования или закупки автономных аппаратных зондов RMON.
Благодаря удобству использования средства пассивной диагностики (метод "от противного") являются основным инструментом для локализации дефектов и "узких мест" сети. С их помощью администратор сети, не сходя со своего рабочего места, может наблюдать за всеми процессами в сети. Однако это далеко не единственная причина.
|
|
|
Скрытые и явние дефекты в локальных сетях
Все многообразие дефектов в локальных сетях можно условно разделить на две категории: "скрытые" и "явные". К категории "явных" относятся дефекты, следствием которых является искажение кадров в процессе их передачи по сети. Дефекты, относящиеся к категории "скрытых", замедляют работу сети, но не вызывают появления искаженных кадров.
Основной причиной искажения кадров в сети являются дефекты пассивного сетевого оборудования и некоторые неисправности приемо-передающих модулей активного сетевого оборудования. По разным оценкам, доля дефектов только пассивного сетевого оборудования составляет от 65 до 85%. В отличие от скрытых, явные дефекты сети достаточно просто обнаружить с помощью средств пассивной диагностики. Для этого все проходящие по сети кадры достаточно проанализировать на предмет наличия в них искажений. Именно преобладание дефектов пассивного сетевого оборудования над другими дефектами сети является одной из причин того, что средства пассивной диагностики оказываются основным инструментом для локализации дефектов сети.
Тенденция развития сетевых технологий такова, что относительная доля явных дефектов постоянно снижается. С одной стороны, это вызвано переходом с коаксиального кабеля на витую пару и оптику, что повышает помехоустойчивость каналов передачи информации. С другой стороны, активное сетевое оборудование становится все более сложным, и это повышает вероятность появления в нем "скрытых дефектов". Вот несколько примеров наиболее распространенных "скрытых дефектов" сети.
"Сетевая плата плохо слышит паузу". Одним из широко распространенных недостатков сетевых плат является дефект, когда датчик паузы в сетевой плате настроен на время, несколько большее, чем 9,6 мкс (для Ethernet). В этом случае, при наличии нескольких активных станций, станция с такой сетевой платой будет ждать более длинной паузы и, следовательно, уступать канал всем остальным станциям, когда те одновременно с ней хотят передавать данные. Свои кадры "глухая" станция будет передавать только в те моменты, когда ни одна другая станция коллизионного домена не имеет кадров для передачи. В результате "глухая станция" будет работать медленней всех остальных станций, однако никаких искаженных кадров в сети не появится.
"Искажение информации после проверки контрольной последовательности CRC". Этот недостаток может встречаться в любом активном сетевом оборудовании и заключается в том, что искажение информации происходит уже после ее приема из сети и проверки CRC. Предположим, что сетевая плата или коммутатор принимает кадр из сети, проверяет поле CRC и, не обнаружив ошибки, передает данные драйверу. Если из-за какой-либо ошибки, например дефекта приемного буфера сетевой платы, данные окажутся искажены, то такое искажение информации может остаться незамеченным сетевой ОС (при отсутствии проверки контрольной суммы на транспортном уровне). Как и в предыдущем случае, никаких искаженных кадров в сети не появится.
"Скрытые дефекты" в микропрограммном обеспечении коммутаторов". Недостатки в микропрограммном обеспечении коммутаторов приводят к удалению кадров из обращения при высокой пиковой нагрузке или к взаимной блокировке портов (высокая пиковая загрузка одного порта вызывает блокировку другого порта). Разработчики пассивных средств диагностики отреагировали на тенденцию увеличения доли "скрытых дефектов" выпуском экспертных систем для обнаружения симптомов "скрытых дефектов". Первой это сделала компания Network General (сейчас Network Associates) в анализаторе протоколов Sniffer, обеспечив себе в течение двух лет доминирующую позицию на рынке анализаторов протоколов. Затем в гонку вступила компания Hewlett-Packard с продуктом LAN Internetwork Advisor, а вслед за ней компания Wandel & Goltermann (сейчас Wavetek Wandel Goltermann) с продуктом Mentor. Сегодня все серьезные игроки на рынке диагностических средств предлагают экспертные системы в качестве интегральной составляющей анализатора сетевых протоколов или дополнительной опции. Таким образом, экспертная система становится обязательным атрибутом для эффективной диагностики сети, что иногда очень существенно удорожает стоимость диагностического средства.
|
|
|
Какие выводы можно сделать на основании низмерений числа искаженных кадров и утилизации сети
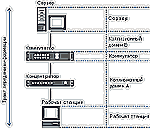
В настоящее время в России наличие экспертной системы у администратора сети является скорее исключением, чем правилом. Большинство администраторов сетей делают выводы о наличии дефектов и "узких мест" в сети только на основании простейших наблюдений за работой сети. Чаще всего это измерения утилизации сети и доли искаженных кадров. Чтобы лучше представлять, какие выводы можно, а какие нельзя сделать на основании измерения утилизации сети и доли искаженных кадров, мы рассмотрим в качестве примера фрагмент упрощенной модели некоторой сети (см. Рисунок 1).
Изображенный на Рисунке 1 фрагмент сети состоит из пяти взаимосвязанных компонентов: рабочей станции, коллизионного домена А, коммутатора, коллизионного домена В, сервера. Каждый коллизионный домен может представлять собой концентратор вместе с кабельной системой (как в домене А) или только полу/полнодуплексное соединение между рабочей станцией/сервером и коммутатором (как в домене В). При этом большинство компонентов сами являются сложными системами.
Так, рабочая станция состоит, как минимум, из двух взаимосвязанных систем: вычислительной платформы и сетевого интерфейса (см. Таблицу). Коммутатор — из трех взаимосвязанных систем: сетевого интерфейса А, вычислительной платформы и сетевого интерфейса В. Сервер — также из трех взаимосвязанных систем: сетевого интерфейса, вычислительной платформы и дисковой системы. Каждая из перечисленных систем состоит из нескольких подсистем. Каждая подсистема может быть потенциальным "узким местом" сети или носителем дефекта. В Таблице показаны 23 такие подсистемы (от 1а до 10с).
Компонент сети |
Система сети |
Подсистема сети |
Сервер |
Дисковая система |
Диски |
10 |
С |
Канал |
В |
Приемо-передающий буферы |
А |
Вычислительная
платформа |
Процессор |
9 |
С |
ОЗУ |
В |
Системная шина |
А |
Сетевой
интерфейс |
Приемо-передающий буферы |
8 |
С |
Системное ПО стека
протокола |
В |
Сетевая плата |
А |
Коллизиционный домен В |
Кабельная система |
7 |
|
Коммутатор |
Сетевой интерфейс В |
|
6 |
|
Платформа |
Приемо-передающий буферы |
5 |
С |
ПО
(микропрограммное
обеспечение) |
В |
Внутренняя
магистраль или матрица |
А |
Сетевой интерфейс А |
|
4 |
|
Коллизиционный домен А |
Кабельная система |
3 |
В |
Концентратор |
А |
Рабочая станция |
Сетевой
интерфейс |
Сетевая плата |
2 |
С |
Приемо-передающий буферы |
В |
Системное ПО стека
протоколов |
А |
Вычислительная
платформа |
Системная шина |
1 |
С |
ОЗУ |
В |
Процессор |
А |
Системы и подсистемы фрагмента сети, изображенного на Рисунке 1. Практически каждая подсистема может быть потенциальным "узким местом" или источником дефекта.
Утверждение №1. При отсутствии или незначительном числе искаженных кадров в сети достоверные выводы можно делать только об отсутствии дефектов в аппаратуре коллизионных доменов сети. В Таблице — это подсистемы 3а, 3b, 7. При этом делать вывод об отсутствии "скрытых дефектов" в остальных компонентах сети нельзя.
Даже при наличии в сети определенного количества искаженных кадров их влияние на работу пользовательских приложений не следует переоценивать. Если кабельная система сети была протестирована, искаженные кадры следует рассматривать, в первую очередь, как симптомы других, более опасных дефектов активного оборудования. В большинстве сетей, диагностику которых мы проводили, доля искаженных кадров редко превышала один процент от общего числа кадров. При этом очень часто сеть имела серьезные дефекты, наличие которых существенно замедляло работу пользовательских приложений.
Утверждение №2. Если утилизация коллизионных доменов (или портов коммутатора) и процессора сервера низкая, то это еще не означает отсутствие в сети "узких мест".
Если глубоко не вдаваться в детали и, в частности, не рассматривать проблему скрытых "узких мест", то для неискушенного взгляда локализация "узкого места" сети представляется относительно простой задачей.
"Узким местом" сети называют обычно ресурс сети с наименьшей пропускной способностью и, следовательно, — с наибольшей загрузкой. Поэтому, измерив утилизацию (степень загрузки) всех ресурсов, вы можете определить наиболее загруженный ресурс. Однако все на самом деле не так просто, здесь мы должны учитывать целый ряд факторов.
Фактор №1. Работа всех систем сети взаимосвязана. Наличие хотя бы одной перегруженной системы влияет на максимальную утилизацию других систем сети.
Например, перегруженная платформа рабочей станции (система 1 в Таблице) ограничивает максимальную утилизацию коллизионного домена А (система 3). Перегруженная дисковая система сервера (система 10) ограничивает максимальную утилизацию сетевого интерфейса сервера (система 8), перегруженная платформа коммутатора — максимальную утилизацию всех систем рабочей станции и сервера и т. д. Поэтому, чтобы локализовать "узкое место" сети, утилизацию всех систем сети требуется измерить в одном временном разрезе. В общем случае анализ только загрузки процессора сервера и коллизионных доменов сети недостаточен для выяснения того, в чем причина низкой загруженности этих систем — в низкой загруженности сети или перегруженности каких-то других систем сети.
Фактор №2. Загрузку ряда систем сети сложно измерить.
Если утилизацию коллизионных доменов (системы 3 и 7) и процессора сервера (система 9) измерить достаточно просто, то утилизацию остальных систем измерить не всегда возможно. Особые сложности могут возникнуть при оценке утилизации платформы коммутатора и сетевого интерфейса сервера. Подобное измерение можно провести только в том случае, если это позволяют возможности активного оборудования. Например, утилизацию сетевого интерфейса сервера можно измерить только при наличии на сетевой плате сервера специального встроенного SNMP-агента (как это сделано, например, в сетевой плате Intel PRO/100+ Server Adapter).
Однако даже при наличии средств для измерения утилизации всех основных систем сети попытка увидеть измеренные значения в едином временном разрезе может натолкнуться на значительные препятствия. Основные выводы, которые мы хотим сделать, заключаются в следующем.
1. |
Эффективность пассивных средств диагностики очень существенно зависит от архитектуры диагностируемой сети и от возможностей активного оборудования по предоставлению информации, характеризующей его работу.
|
2. |
Для локализации всех дефектов и "узких мест" сети проведение измерений только утилизации сети и доли искаженных кадров может оказаться недостаточно.
|
Теперь самое время вернуться к задаче, которую мы сформулировали в начале статьи: как с помощью пассивных средств диагностики определить, почему пользовательские приложения работают медленно или сбоят?
Традиционно данную задачу принято решать с помощью анализатора сетевых протоколов с поддержкой декодирования всех протоколов, включая протоколы прикладного уровня, и "умной" экспертной системы с возможностью выявления симптомов не только "скрытых дефектов" и перегрузки сервера, но и неэффективной работы пользовательских приложений. Примерами таких средств являются аппаратные анализаторы серии Domino и экспертная система Mentor компании Wavetek Wandel Goltermann, а также HP LAN Internetwork Advisor.
Такой путь вполне реален и практичен, если пользовательские приложения вашей сети работают со стандартными прикладными протоколами, например, если пользовательские приложения написаны на Oracle, Sybase и т. п. Однако в России доля приложений на базе стандартных прикладных протоколов незначительна, как и число компаний, которые могут позволить себе приобрести диагностическое средство стоимостью около 25 000 долларов.
Однако данную задачу можно попытаться решить другим, несколько более "дешевым" способом. Естественно предположить, что если дефекты и "узкие места" в сети отсутствуют, то приложения должны работать быстро и устойчиво. Если в процессе диагностики сети вы достоверно определите, что в сети нет "скрытых дефектов" и "узких мест", значит "виноваты" пользовательские приложения. Теоретически эту задачу можно решить, используя менее дорогие, чем в первом случае, средства диагностики. Однако для этого необходимо наличие, как минимум, четырех составляющих.
Во-первых, анализатор сетевых протоколов с поддержкой декодирования всех протоколов до транспортного уровня включительно и "умная" экспертная система для выявления "скрытых дефектов" сети. Примером такого анализатора протоколов и экспертной системы могут служить, например, Observer v.6.1 и Expert Extension компании Network Instruments. Во-вторых, программы на базе SNMP (например, SNMP Extension и RMON Extension компании Network Instruments) для сбора информации от встроенных в активное оборудование зондов RMON. В-третьих, и это особенно важно, зонды RMON на всех компонентах тракта "рабочая станция—сервер" (см. Таблицу). В-четвертых, эксперт, который сможет правильно интерпретировать полученные с помощью этих средств результаты. Третий способ решения поставленной задачи заключается в сочетании метода пассивной диагностики и метода активного тестирования сети. Он предполагает наличие относительно недорогого анализатора сетевых протоколов или программы на базе SNMP и специальных тестов для измерения скорости работы сети. Если в качестве критерия эффективности рассматривать "оперативность решения задачи/(стоимость * сложность)", то, с нашей точки зрения, данный способ является наиболее эффективным. Его-то мы и собираемся рассмотреть более подробно.
|
|
|
Метод активного тестирования расширяет возможности средств пассивной диагностики
Метод активного тестирования сети состоит в том, что выводы о наличии в сети "скрытых дефектов" и "узких мест" делаются не только в результате пассивного наблюдения за работой сети, но и на основании измерений скорости работы сети в процессе ее эксплуатации.
Методология активного тестирования в чем-то аналогична поиску неисправностей в электронном устройстве. Профессиональный электронщик редко ограничивается методом "от противного". Поиск неисправностей обычно только начинается с проверки наличия или отсутствия сигналов в неких опорных точках (метод "от противного"). При отсутствии результата первичной проверки электронщик, как правило, устанавливает генератор сигналов или запускает тестовую программу и, в соответствии с принципиальной электрической схемой устройства, проверяет прохождение сигналов по всем цепям. Другими словами, зная, как устройство должно работать, он проверяет, как оно реально работает. А это уже не метод "от противного", а метод активного тестирования. Давайте задумаемся, что дает метод активного тестирования применительно к диагностике сетей. На самом деле, измеряя такие характеристики работы сети, как утилизация сети и сервера, число ошибок на канальном и транспортном уровне, доля широковещательных кадров и многое другое, мы прежде всего думаем о том, какое влияние все эти характеристики оказывают на скорость работы сети. Другими словами, все измеряемые пассивными средствами диагностики характеристики являются, по сути, косвенными признаками того, как работает сеть. Основным же или "прямым" показателем состояния сети служит именно скорость сети, т. е. то, как быстро сеть обрабатывает заявки пользовательских приложений. Поэтому зная, с какой скоростью сеть должна работать, и измерив, как сеть реально работает, мы можем сделать выводы о факте наличия в сети дефектов или "узких мест". После этого более детальная локализация дефектов и "узких мест" осуществляется средствами пассивной диагностики.
Как измерить скорость сети? Это не столь тривиальная задача, как может показаться на первый взгляд. Тестовое приложение для измерения скорости сети должно удовлетворять следующим основным требованиям.
Требование №1. Тестовое приложение должно измерять реальную скорость сети. В частности, измеряемые значения скорости не должны зависеть от объема кэш-памяти компьютера, где оно выполняется. Иначе измеренные значения будут недостоверны.
Требование №2. Тестовое приложение должно тестировать весь тракт "рабочая станция—сервер", начиная от вычислительной платформы рабочей станции (система 1 в Таблице) и заканчивая дисковой системой сервера (система 10 в Таблице). Другими словами, наличие "скрытого дефекта" или "узкого места" в любой системе тракта "рабочая станция—сервер" не должно остаться незамеченным для тестового приложения.
Требование №3. Тестовое приложение должно быть таким, чтобы в случае наличия дефекта или "узкого места" в любой системе тракта "рабочая станция—сервер" оно позволяло локализовать источник проблемы.
Требование №4. Работа тестового приложения не должна существенным образом сказываться на функционировании пользовательских приложений в сети. Другими словами, тестовое приложение должно оказывать как можно меньше влияния на работу всех систем сети, за исключением компьютеров, на которых оно выполняется.
"Скорость сети" следует отличать от "пропускной способности сети". Под пропускной способностью сети (throughput) принято понимать максимальный объем данных, который сеть может передать за фиксированный промежуток времени. Под скоростью сети в данной статье мы будем понимать скорость выполнения файловых операций. Скорость выполнения файловой операции получается при делении длины дисковой записи (в килобайтах) на время ее чтения/записи (в секундах). Полученные значения усредняются за заданный временной интервал. Таким образом, под скоростью сети мы будем понимать время реакции сети при выполнении файловых операций.
Выбор именно файловых операций обусловлен следующим. Файловые операции являются наиболее распространенным типом операций прикладного уровня сети. Большинство используемых в России приложений базируется именно на файловых операциях. Кроме того, анализ скорости выполнения файловых операций числа ошибок прикладного уровня проверяет функционирование всего стека протоколов на рабочей станции и сервере, а также всех систем тракта "рабочая станция—сервер", в том числе, что особенно важно, дисковой системы сервера (Требование №2). Далее, если скорость выполнения файловых операций недопустимо низкая или наблюдаются ее "провалы", то причину этого определить легко, так как в качестве транспортного протокола при файловых операциях чаще всего используются TCP/IP, IPX/SPX, NetBEUI, а эти протоколы дешифруются практически всеми анализаторами сетевых протоколов (Требование №3).
Многие могут справедливо возразить, что в общем случае "скорость сети" и "скорость выполнения файловых операций в сети" — это не одно и то же. Это действительно так. Однако скорость выполнения файловых операций является, с нашей точки зрения, наилучшим и наиболее универсальным критерием, на основании которого можно судить о скорости сети. Задавая различные параметры файловых операций, такие, как размер записи, объем файла, процентное соотношение операций чтения и записи, мы можем нагружать и, тем самым, проверять различные системы сети. Поэтому в данной статье понятия "скорость сети" и "скорость выполнения файловых операций в сети" мы будем употреблять как синонимы.
Измерения скорости выполнения файловых операций можно проводить с помощью различных средств. В своей практической работе мы используем специально разработанный компанией "ПроЛАН" программный пакет FTest (см. врезку "Как работает FTest"). В частности, для выяснения того, кто виноват в медленной работе приложений, — сеть или недостатки самих пользовательских приложений, мы используем программу Long term FTest из пакета FTest v.3.1. Программа Long term FTest удовлетворяет всем приведенным выше требованиям. Упрощенный алгоритм решения этой задачи с использованием пакета FTest приведен ниже.
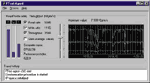
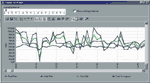
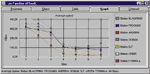
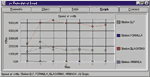
На одной или нескольких станциях сети запускается тестовое приложение (FTest Client в режиме Long term), когда сеть эксплуатируется в своем обычном режиме. Программу Long term FTest целесообразно запускать, в первую очередь, на тех станциях сети, пользователи которых чаще других жалуются на плохую работу сети. Она позволяет получить информацию о текущей скорости сети, т. е. о скорости за короткие интервалы времени (см. Рисунок 2), и о долговременной скорости сети, т. е. об изменении скорости сети за длительные промежутки времени, например в течение рабочего дня (см. Рисунок 3). Программа сообщит также и об ошибках прикладного уровня, которые она зафиксировала в процессе своей работы.
Цель эксперимента заключается в следующем. Во-первых, измерить, каково абсолютное значение скорости сети. Во-вторых, определить, как скорость работы сети изменяется с течением времени в процессе эксплуатации сети (при работе пользовательских приложений). В-третьих, установить, совпадает ли по времени замедление работы пользовательских приложений с "провалами" в скорости работы сети.
Если в процессе работы программы Long term FTest будет выявлено, что абсолютное значение скорости сети находится в допустимых пределах, а четкая зависимость между скоростью работы сети и периодами медленной работы пользовательских приложений не прослеживается, то это будет означать, что сеть "не виновата" в медленной работе пользователей сети. Другими словами, если сеть работает быстро, когда пользовательские приложения работают медленно, то, вероятнее всего, вина лежит на самих пользовательских приложениях. Если же в процессе работы программы Long term FTest будет выявлено, что пользовательские приложения работают медленно именно в те периоды времени, когда скорость работы в сети низкая, то это будет означать, что в медленной работе пользователей "виновата" в том числе и сеть. При этом, если абсолютное значение скорости сети оказывается неприемлемо низким вне зависимости от работы пользовательских приложений, то, вероятно, это связано с недостатками архитектуры сети. Наличие же "провалов" скорости означает, что какая-то система сети перегружена или имеет место дефект.
Такой метод доказательства "виновности" или "невиновности" приложений нельзя считать абсолютно достоверным. Однако наша практика показывает, что в большинстве случаев он дает правильные результаты. Следует особо отметить, почему для определения причин медленной работы пользовательских приложений не следует использовать программы, в которых пропускная способность сети измеряется методом "перекачки" файлов между рабочей станцией и сервером.
Если на компьютерах, работающих в среде Windows 95/98/NT, вы попытаетесь измерить реальную скорость сети в процессе работы пользовательских приложений методом "перекачки" файлов, то результаты будут приблизительно следующими. Если вы будете перекачивать файлы небольших размеров (соизмеримые с кэш-памятью рабочей станции), то тогда измеряемая величина будет не реальной скоростью сети, а пропускной способностью компьютера при работе приложения с кэш-памятью рабочей станции. В результате полученные цифры могут на порядок и более превышать реальную величину скорости сети.
Казалось бы, подобную неопределенность можно устранить посредством перекачки файлов, размер которых существенно превышает объем кэш-памяти на рабочей станции. Однако в этом случае, во-первых, вы сильно загрузите сеть, что повлияет на работу пользовательских приложений (Требование №4). Во-вторых, при перекачке больших файлов сетевая ОС работает в режиме блочной передачи пакетов (режим burst mode). В результате вы будете измерять не скорость, а пропускную способность сети. При этом полученные значения будут в несколько раз превышать те скорости, с которыми реально работают пользовательские приложения. Практические выводы в свете поставленной задачи вам сделать вряд ли удастся.
Мы хотим также обратить ваше внимание на то, почему при поиске дефектов в локальных сетях использование утилит на основе ICMP далеко не всегда оказывается целесообразным. Подобные утилиты незаменимы в тех случаях, когда необходимо определить наличие или отсутствие связи между станциями сети. Однако они предоставляют очень мало полезной информации, когда требуется локализовать "скрытые дефекты" и "узкие места" в локальных сетях, следствием которых является медленная или неустойчивая работа приложений в сети. Причина заключается в отсутствии в протоколе ICMP механизмов повторных передач (retransmissions) и управления потоком данных (flow control). В результате вы не всегда сможете определить, почему пакеты ICMP вдруг перестали проходить от одной станции к другой. Кроме того, ни одно реальное пользовательское приложение не работает на базе протокола ICMP.
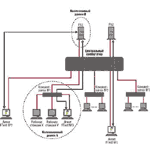
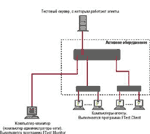
Вернемся к поставленной в начале статьи задаче. Предположим, что, измерив скорость сети, вы определили, что при отсутствии пользовательских приложений скорость сети высока и что "провалы" скорости работы сети в большинстве случаев совпадают по времени со сбоями в работе пользовательских приложений. В этом случае вам предстоит выяснить причину "провалов". Это можно сделать с помощью пассивного средства диагностики, например анализатора сетевых протоколов. Однако, прежде чем браться за диагностику, с помощью ряда простых экспериментов вы можете существенно сузить область поиска источника проблемы и тем самым упростить задачу. Предположим, что ваша сеть имеет архитектуру, представленную на Рисунке 4. В состав сети входит центральный коммутатор 10/100, два сервера, каждый из которых связан с коммутатором полнодуплексным каналом Fast Ethernet, три концентратора и 19 станций, подключенных к коммутатору по каналам Ethernet. Остальные станции сети подключены к трем концентраторам. Предположим также, что пользователи Х и Y, расположенные в коллизионном домене А, чаще других жалуются на медленную работу своих приложений при обращении к серверу FS1.
Для сети, изображенной на Рисунке 4, источник проблемы может быть в коллизионном домене А, где расположены компьютеры пользователей Х и Y, в центральном коммутаторе или в коллизионном домене В, включающем сервер FS1. Чтобы локализовать область поиска, необходимо запустить три агента (три приложения FTest Client в режиме Long term) с одинаковыми параметрами генерации трафика. При этом агент №1 должен работать на компьютере в "подозрительном" коллизионном домене А и быть настроен на работу с "подозрительным" сервером FS1. Агент №2 должен выполняться на непосредственно подключенном к центральному коммутатору компьютере и настроен на работу с "подозрительным" сервером FS1. Агент №3 может работать на компьютере, расположенном в любом другом разделяемом домене (кроме домена А) или быть непосредственно подключен к центральному коммутатору, но настроен на работу с сервером FS2.
Пакет FTest разработан таким образом, что работа всех агентов синхронизирована. Это означает, что в любой момент времени вы можете увидеть скорость работы каждого агента с привязкой к единой временной шкале. Поэтому если в процессе работы агентов вы увидите, что "провалы" в скорости работы агента №1 чаще всего происходят в те моменты времени, когда агент №2 и агент №3 работают устойчиво ("провалов" скорости не наблюдается), то источник проблемы, вероятнее всего, находится в коллизионном домене А. Если "провалы" в скорости работы агента №1 чаще всего совпадают по времени с "провалами" в скорости работы агента №2, но агент №3 в эти моменты времени работает устойчиво, то источник проблемы, вероятнее всего, в коллизионном домене В, в том числе на сервере FS1. Если же скорость работы всех трех агентов падает одновременно, то причину следует искать в центральном коммутаторе.
Если вы выяснили, что проблема в центральном коммутаторе, то выбор возможных действий невелик. Первое, с чего целесообразно начать, — это определить общую ("агрегативную") загрузку коммутатора и, сравнив полученное значение с паспортными данными на коммутатор, установить, не перегружен ли он. В общем случае это можно сделать с помощью telnet или SNMP, если позволяет коммутатор. В анализаторе протоколов Observer v.6.1 для таких измерений предусмотрена специальная функция. Если выяснится, что общая загрузка невелика, то вам остается попробовать другие режимы коммутации или обновить микропрограммное обеспечение коммутатора.
Если вы определили, что проблема в дефекте или недостаточной производительности сервера, то задачу следует решать с помощью штатных средств мониторинга сервера, совместно с анализатором сетевых протоколов. Рассмотрение методики выявления "узких мест" и дефектов в сервере выходят за рамки данной статьи. Однако мы хотим обратить ваше внимание на то, что использование пакета FTest существенно упрощает задачу локализации "узких мест" и "скрытых дефектов" в сервере. И вот почему.
При применении только пассивных средств диагностики выводы об адекватности сети пользовательским приложениям делаются на основании измерения характеристик работы сети (и сервера) во время функционирования пользовательских приложений. И это понятно, поскольку, в конечном счете, целью диагностики сети является выяснение причин медленной работы именно пользовательских приложений. Однако интерпретация результатов измерений затрудняется тем, что не всегда ясно, как в момент снятия характеристик функционирования сервера работает пользовательское приложение. Если же было установлено, что медленная работа пользовательских приложений коррелирует по времени с медленной работой тестового приложения, то задача существенно упрощается. Одновременно наблюдая за скоростью работы сети и характеристиками работы сервера (например, с помощью Performance Monitor), вы всегда можете сопоставить друг с другом скорость сети и характеристики работы сервера. Зафиксировав "провал" скорости сети, вы всегда можете выяснить и значения характеристик работы сервера на момент этого "провала".
Если в результате предварительного анализа будет выявлено, что причина "провалов" скорости в коллизионном домене, то программа на основе SNMP или даже очень "умный" анализатор сетевых протоколов могут и не позволить выявить "скрытый дефект". Это относится, прежде всего, к тем случаям, когда "скрытый дефект" находится на компьютерах рабочих станций. Поскольку ни один анализатор протоколов не знает, как должно работать пользовательское приложение, он не сможет провести различие между медленной работой станции вследствие специфики пользовательского приложения и медленной работой в результате дефекта компьютера (естественно, при отсутствии явных симптомов дефекта). В этом случае может помочь стрессовое тестирование сети.
|
|
|
Стрессовое тестирование как средство локализации "скрытых дефектов" сети
Метод стрессового тестирования сети является частным случаем метода активного тестирования сети. Полезность этого метода для выявления "скрытых дефектов" и "узких мест" сети сложно переоценить. Однако у метода стрессового тестирования сети есть один серьезный недостаток: его можно применять, только когда в сети нет других работающих пользователей (аналогично процедуре тестирования кабельной системы).
Ниже мы кратко рассмотрим только методику выявления с помощью стрессового тестирования ряда "скрытых дефектов" сети, когда их сложно выявить другими способами. В следующей статье мы планируем рассказать об использовании этого метода для выявления "узких мест" сети. Придерживаясь стилистики предыдущих статей, мы рассмотрим метод "стрессового тестирования" как набор правил, которым должна удовлетворять сеть при отсутствии "скрытых дефектов".
Правило №1. Если в каждый момент времени в сети работает только одна пара сервер—агент (приложения FTest Client) и в компьютерах, сетевом оборудовании и кабельной системе дефекты отсутствуют, то скорость работы каждого агента должна быть прямо пропорциональна индексу производительности компьютера агента. При этом компьютеры агентов должны иметь одинаковую конфигурацию (тип сетевой платы, объем оперативной памяти). Другими словами, если все агенты работают строго по очереди, то высокопроизводительные компьютеры должны работать в сети быстро, а низкопроизводительные — медленнее.
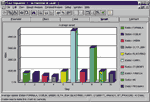
Тест FTest by steps из пакета FTest можно настроить таким образом, что все агенты будут работать с одинаковой интенсивностью и типом трафика, причем строго по очереди. Один из результатов такого теста показан на Рисунке 5. Поскольку каждый агент перед началом теста определяет тип сетевой платы и конфигурацию компьютера и вычисляет индекс его производительности, проверить выполнение данного правила не составляет труда.
Если вы обнаружите, что какой-то компьютер работает медленнее, чем ожидалось, то это будет служить симптомом дефекта. В общем случае это может быть дефект самого компьютера или канала связи. Если одновременно с выполнением программы FTest вы будете наблюдать за работой сети с помощью анализатора сетевых протоколов, то легко сможете отделить одно от другого.
Поскольку в каждый момент времени в сети работают только два взаимодействующих друг с другом компьютера (агент и сервер), ни коллизий, ни канальных ошибок в сети быть не должно, поскольку компьютеры синхронизированы друг с другом. При такой работе сети все ошибки и коллизии могут быть только следствием дефектов активного или пассивного оборудования. Таким образом, вы косвенно проверите еще и качество кабельной системы и активного оборудования. В частности, вы проверите качество контактов между активным и пассивным оборудованием (при тестировании кабельной системы кабельным сканером оно не проверяется). Если число ошибок в канале не будет превышать 0,001% от общего числа переданных по сети кадров, то в кабельной системе и приемо-передающих блоках активного оборудования дефектов нет. Следовательно, дефект следует искать в самом компьютере.
Правило №2. Если в компьютерах, сетевом оборудовании и кабельной системе дефекты отсутствуют, то число ошибок канального уровня не должно увеличиваться с ростом нагрузки в сети. При этом скорость агентов должна плавно снижаться при увеличении предлагаемой нагрузки. Крутизна снижения скорости агентов с одинаковой конфигурацией компьютеров (объем оперативной памяти, тип сетевой платы) должна быть обратно пропорциональна индексу производительности компьютеров.
Тест FTest all stations из пакета FTest можно настроить таким образом, что все агенты будут работать одновременно, постепенно увеличивая нагрузку на сеть. На Рисунке 6 показан один из результатов такого теста. Если при работе теста FTest all stations вы обнаружите, что скорость работы отдельных агентов снижается быстрее, чем скорость работы других агентов с идентичной конфигурацией и индексом производительности, то это свидетельствует о наличии дефекта в конкретных компьютерах или сетевом оборудовании, к которому эти агенты подключены. Чтобы отделить одно от другого, мы рекомендуем воспользоваться анализатором сетевых протоколов.
Если при работе теста вы установите, что число ошибок при передаче данных на канальном уровне увеличивается с ростом предлагаемой нагрузки, то это свидетельствует о наличии в сети агента (агентов) с неисправной сетевой платой. Определить конкретного виновника можно двумя способами. Первый способ заключается в анализе МАС-адресов станций — источников искаженных кадров. Этот способ не всегда работает, так как ошибки могут происходить раньше, чем адрес источника станции будет передан в канал связи. Второй способ заключается в использовании теста FTest by steps.
Тест FTest by steps можно настроить таким образом, что все агенты будут работать с одинаковой нагрузкой и типом трафика, при этом число одновременно работающих агентов постепенно увеличивается. Сначала работает один агент, затем к нему присоединяется второй, третий и т. д. Анализируя число ошибок с помощью анализатора протоколов, вы сможете легко определить, при "вступлении в игру" какого агента в сети начнут появляться ошибки.
В заключение мы хотим рассказать об одной типичной ошибке при внедрении сетей Fast Ethernet. Чтобы увеличить производительность сети, многие компании внедряют технологию Fast Ethernet на рабочих станциях, не задумываясь о последствиях и не проводя тестирование сети. После этого, к их удивлению, пользовательские приложения не только не начинают работать быстрее, а, наоборот, выполняются медленнее. При этом никаких явных дефектов не наблюдается.
Для сравнения мы приводим графики скорости работы сети как функции нагрузки одной и той же сети с сетевыми платами Ethernet 10/100 (см. Рисунки 6 и 7). В первом случае сеть содержит концентратор Ethernet, а во втором — концентратор Fast Ethernet. Обратите внимание, что скорость работы агента Formula близка к нулю. Причина столько низкой скорости объясняется недостаточной производительностью компьютера для работы в сети Fast Ethernet.
Как показывает наш опыт, сети многих компаний работают с очень низким КПД. При тестировании мы неоднократно сталкивались с сетями Ethernet, скорость работы отдельных станций в которых не превышала 20—30 Кбайт в секунду, что в 20—25 раз ниже нормальной скорости сети Ethernet. При этом, ориентируясь только по лампочкам коллизий и ошибок на концентраторах и показаниях консоли сервера, администраторы сетей не видели каких-либо симптомов дефектов или "узких мест" в своей сети. Вся вина возлагалась на прикладное ПО.
Надеемся, что кому-то данная статья поможет ликвидировать имеющиеся в сети дефекты и "узкие места", а кому-то — реабилитировать прикладное ПО.
 |
|
|
Как работает FTest
Пакет FTest 3.1 включает четыре программы. Две программы —FTest Monitor и FTest Client — используются для проведения тестирования сети. Другие две программы — Repgen и FTest Organizer — предназначены для обработки полученных результатов.
Программа FTest Client служит для генерации тестового сетевого трафика и измерения различных характеристик сети (времени реакции, пропускной способности и др.). Эта программа устанавливается и запускается на тех станциях сети, работу которых вы хотите проверить. Такие станции мы будем называть станции-агенты (или просто агенты). Смотри Рисунки 8, 9.
Программа FTest Client осуществляет генерацию трафика и измерение характеристик работы сети на прикладном уровне (скорость работы приложения). Это означает, что генерируемые данные проходят через весь стек протоколов на рабочей станции и сервере. При этом программа написана таким образом, что передаваемые агентом данные обходят кэш-память компьютера. Это позволяет измерять реальные значения скорости и пропускной способности сети, так как иначе программа измеряла бы скорость работы приложения с кэш-памятью агента, а не скорость работы приложения в сети.
Программа FTest Monitor используется для управления процессом тестирования сети. FTest Monitor инсталлируется только на одной рабочей станции сети. Такую станцию будем называть станция-монитор (или просто монитор). Обычно это компьютер администратора сети.
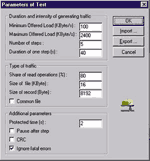
Управление процессом тестирования сети заключается в следующем. Администратор с консоли монитора задает параметры, в соответствии с которыми все агенты будут производить генерацию трафика в сеть. Эти параметры автоматически передаются по сети всем агентам. Пример диалога для задания параметров изображен на Рисунке 10.
Весь перечень задаваемых при запуске каждого теста параметров можно условно разделить на три категории: параметры для определения типа генерируемого трафика (типа файловых операций), параметры для задания длительности и интенсивности генерируемого трафика, дополнительные служебные параметры.
Монитор осуществляет синхронизацию работы всех агентов: каждый агент начинает и заканчивает генерацию трафика и измерение характеристик работы сети, только получив соответствующий сигнал от монитора. Каждый агент определяет конфигурацию компьютера, на котором он работает: тип процессора, объем оперативной памяти, тип сетевой платы и т. п. В процессе генерации трафика каждый агент измеряет характеристики своей работы, в частности скорость выполнения файловых операций (время реакции), пропускную способность, число ошибок прикладного уровня сети. В ходе теста и по его завершении все агенты передают результаты всех своих измерений монитору. Кроме того, и на это мы хотим особо обратить ваше внимание, каждый агент перед началом любого теста измеряет производительность компьютера, на котором он работает.
Пакет FTest v. 3.1 позволяет проводить три типа тестов: FTest all stations, FTest by steps, Long term FTest. Каждый тест представляет собой отдельный программный модуль.
Тесты FTest all stations и FTest by steps предназначены для тестирования сети при отсутствии работающих пользователей. Они, как правило, создают в сети высокую нагрузку. Основное их назначение — измерение общей пропускной способности сети для обнаружения "скрытых дефектов" и выявления "узких мест" сети. Эти тесты отличаются друг от друга только алгоритмом генерации агентами трафика в сеть. В тесте FTest all stations все агенты производят генерацию трафика одновременно, постепенно увеличивая его интенсивность. В тесте FTest by steps все агенты генерируют трафик с постоянной интенсивностью, но число одновременно генерирующих трафик агентов увеличивается постепенно. Одним из режимов данного теста является такой режим, когда все станции работают строго по очереди.
Тест Long term FTest предназначен для измерения скорости сети в процессе ее эксплуатации. Основное его назначение — определить, как скорость работы сети изменяется во время работы пользовательских приложений. При работе этого теста каждый агент осуществляет генерацию трафика в сеть с постоянной заданной интенсивностью в течение длительного времени (например, рабочего дня, недели, месяца и т. д.).
|
 |
наверх
|
|