|
|
|
|
| |
 к выбору публикации к выбору публикации
|
|
|
Увидеть слона целиком. Часть I
С. С. Юдицкий,
В. И. Швецов |
 |
Диагностика сети — это... Помните притчу о том, как слепых подвели к слону и попросили ответить на вопрос, как он выглядит? Один потрогал его ноги и сказал, что слон похож на дерево, другой потрогал хобот и сказал, что слон похож на змею, и т. д. В положении таких же слепых оказываемся и мы, если у нас нет инструментов, позволяющих увидеть сеть как единую систему. Поэтому неудивительно, что одни под диагностикой сети понимают только диагностику кабельной системы, другие — диагностику ошибок передачи данных в канале связи и т. п.
Сеть является сложной системой, в состав которой входит множество компонентов: кабельная система, активное оборудование, сетевая операционная система и многое другое. Поэтому, чтобы оценить качество ее работы, необходимо не только провести анализ функционирования всех ее компонентов, но и правильно обобщить полученные результаты. Только в этом случае можно быть уверенными, что “мы видим слона целиком”.
Задача диагностики была бы обычной процедурой, если бы в каждом компоненте сети устанавливались “датчики”, показывающие его состояние. Снимаешь показания всех “датчиков”, — и сразу становится ясно, хорошо или плохо работает сеть. К сожалению, пока эти мечты из разряда утопий. Учитывая возможности современных средств диагностики, можно выделить лишь несколько основных “точек”, с которых можно оценивать работу сети. К их числу относятся: кабельная система, канал связи (проходящий по сети трафик), сервер (ОС сервера), рабочая станция (ОС рабочей станции), прикладная программа, выполняющаяся на рабочей станции или сервере. Иногда в качестве отдельной “точки наблюдения” выделяют и СУБД. Однако мы этого делать не будем, поскольку СУБД можно рассматривать и как часть прикладной программы. Таким образом, чтобы увидеть сеть “целиком”, мы должны последовательно посмотреть на нее со всех этих “точек”.
Согласитесь, что диагностика любого сложного объекта, будь то кабельная система сети, рабочая станция или прикладная программа, всегда включает в себя три составные части:
1. |
Знание того, как диагностируемая система должна работать.
|
2. |
Получение набора характеристик реальной работы системы. Умение измерить, как диагностируемая система реально работает.
|
3.
| Способность определить, почему диагностируемая система работает не так, как должна.
|
Возвращаясь к перечисленным выше “точкам наблюдения”, заметим, что наиболее легко задача диагностики решается для кабельной системы. Причина этого очень проста: большинство кабельных сканеров (или кабельных тестеров) реализуют все три вышеупомянутые составляющие. Стандарты регламентируют, как кабельная система должна работать, сканер измеряет, как она реально работает, и автоматически определяет, соответствует ли реальная работа требованиям стандартов, и если нет, то почему.
Когда же мы переходим к другим “точкам наблюдения”, задача становится менее тривиальной. В рамках одной статьи невозможно рассмотреть вопросы диагностика всех компонентов сети. Этому будет посвящен цикл статей, в первой из которых мы остановимся на методологии сквозной (End-to-End) диагностики сетей и проиллюстрируем ее на примере диагностики каналов связи сети. В следующих публикациях мы планируем рассказать о методике диагностики рабочих станций, прикладных программ и серверов, при этом мы не будем затрагивать вопросы диагностики кабельной системы.
|
 |
Различные подходы к диагностике, или “Как смотреть на слона”
При диагностике сетевого устройства (или компонента сети) применяют различные подходы. Выбор конкретного подхода зависит от того, что выбирается в качестве критерия хорошей работы устройства. Как правило, можно выделить три типа критериев и, следовательно, три основных подхода.
Первый основан на контроле текущих значений параметров, характеризующих работу диагностируемого устройства. Критериями хорошей работы устройства в этом случае являются рекомендации его производителя, или так называемые промышленные стандарты де-факто. (Подробнее о некоторых из них мы скажем ниже.) Основными достоинствами указанного подхода являются простота и удобство при решении наиболее распространенных, но, как правило, относительно несложных проблем. Однако бывают случаи, когда даже явный дефект боўльшую часть времени не проявляется, а дает о себе знать лишь при некоторых, относительно редких режимах работы и в непредсказуемые моменты времени. Обнаружить такие дефекты, контролируя только текущие значения параметров, весьма затруднительно.
Второй подход основан на исследовании базовых линий параметров (так называемых трендов), характеризующих работу диагностируемого устройства. Основной принцип второго подхода можно сформулировать следующим образом: “устройство работает хорошо, если оно работает так, как всегда”. На этом принципе основана упреждающая (proactive) диагностика сети, цель которой — предотвратить наступление ее критических состояний. Противоположной упреждающей является реактивная (reactive) диагностика, цель которой не предотвратить, а локализовать и ликвидировать дефект. В отличие от первого, данный подход позволяет обнаруживать дефекты, проявляющиеся не постоянно, а время от времени. Недостатком второго подхода является предположение, что изначально сеть работала хорошо. Но “как всегда” и “хорошо” не всегда означают одно и то же.
Третий подход осуществляется посредством контроля интегральных показателей качества функционирования диагностируемого устройства (далее — интегральный подход). Следует подчеркнуть, что с точки зрения методологии диагностики сети между первыми двумя подходами, которые будем называть традиционными, и третьим, интегральным, есть принципиальное различие. При традиционных подходах мы наблюдаем за отдельными характеристиками работы сети и, чтобы увидеть ее “целиком”, должны синтезировать результаты отдельных наблюдений. Однако мы не можем быть уверены, что при этом синтезе не потеряем важную информацию. Интегральный подход, наоборот, дает нам общую картину, которая в ряде случаев бывает недостаточно детальной. Задача интерпретации результатов при интегральном подходе, по существу, обратная: наблюдая целое, выявить, где, в каких частностях заключается проблема.
Из сказанного следует, что наиболее эффективен подход, совмещающий функциональность всех трех описанных выше подходов. Он должен, с одной стороны, основываться на интегральных показателях качества работы сети, но, с другой — дополняться и конкретизироваться данными, которые получаются при традиционных подходах. Именно такая комбинация позволяет и “увидеть слона целиком”, и поставить точный диагноз его болезни. Такой подход заложен в программном пакете FTest Pro компании ProLAN.
Далее мы рассмотрим, как перечисленные выше подходы реализуются в диагностических средствах, предназначенных для оценки качества работы каналов связи сети. Под каналом связи сети мы будем понимать следующую совокупность компонентов: все активное сетевое оборудование (концентраторы, коммутаторы и т. п.), все пассивное сетевое оборудование (кабельная система) и сетевое оборудование, установленное на сервере.
|
|
|
Достоинства и недостатки традиционных подходов
Обычно выводы о качестве работы каналов связи делаются на основе анализа сетевого трафика, т. е. на анализе всех проходящих по каналу связи пакетов. Различные диагностические средства позволяют осуществлять это с различной степенью детализации. Можно выделить три основных уровня такой детализации: сбор статистической информации, декодирование протоколов, проведение экспертного анализа трассировки.
Статистическая информация представляет собой первичный уровень детализации. Статистика может быть текущей (интервал усреднения информации — порядка секунды) и долговременной (интервал усреднения информации — от одной минуты до нескольких часов). Текущая статистика позволяет определить, как сеть работает в данный момент времени. Долговременная статистика позволяет построить так называемый тренд (trend), или тенденцию.
Статистическую информацию о сетевом трафике позволяют получить практически все диагностические средства. В России для этих целей традиционно использовались пакеты LANalyzer for Windows компании Novell и NetXRay компании Cinco (ныне в составе Network Associates).
В настоящее время их место занял пакет Observer компании Network Instruments. Диагностика каналов связи сети на основе текущей статистической информации о сетевом трафике как раз и является реализацией подхода, основанного на текущих значениях параметров. Диагностика каналов связи сети на основе долговременной информации о сетевом трафике — это реализация второго подхода, т. е. подхода, основанного на исследовании базовых линий.
При анализе статистической информации о сетевом трафике контролируемыми параметрами являются: загрузка канала связи сети, общее число ошибок передачи данных и распределение их по станциям, распределение станций сети по числу и типу переданных в сеть пакетов, распределение пакетов по протоколам, распределение пакетов по длинам и т. п.
Основным критерием качества работы сети в этих случаях является соответствие контролируемых параметров так называемым промышленным стандартам. Это стандарты де-факто, регламентирующие, например, чтобы загрузка разделяемого канала связи сети Ethernet в течение длительного периода времени не превышала 35%, доля ошибочных пакетов — 0,01% от общего числа пакетов, доля широковещательных и групповых пакетов — 8—10% от общего числа пакетов и т. д.
Анализ статистической информации позволяет решить ряд часто встречающихся, но относительно несложных сетевых проблем. Это локализация дефектных компонентов сети, являющихся причиной искажения передаваемых по ней пакетов; определение перегруженности сети; выяснение причин “широковещательного шторма”; нахождение станций, которые неэффективно используют сеть, загружают ее наиболее сильно и др. У всех этих проблем есть одно общее качество: их легко “увидеть” путем анализа сетевого трафика. Их причинами, как правило, являются дефекты кабельной системы, активного оборудования или архитектуры сети. Дефекты сети, которые можно выявить путем анализа статистической информации о сетевом трафике, будем называть явными. Таким образом, анализ статистической информации является эффективным средством локализации явных дефектов сети.
Если загрузка сети низкая, ошибок нет, отсутствует широковещательный шторм, — другими словами, явных дефектов нет, означает ли это, что сеть работает хорошо? Как вы уже, наверное, догадались, нет. Кроме явных дефектов, в сети может быть большое число так называемых скрытых дефектов. С их примерами вы можете ознакомиться в разделе http://www.netconsulting.ru/knowledgebase/about/index.html.
Скрытые дефекты невозможно локализовать, анализируя только статистическую информацию о сетевом трафике. Это можно сделать с помощью более детального его анализа. Таковым является захват сетевых пакетов и декодирование содержащихся в них данных (декодирование сетевых протоколов), т. е. запись в буфер диагностического средства содержимого проходящих по сети пакетов. Декодируя содержащиеся в пакете данные, можно получить много полезной информации о работе протоколов транспортного и прикладного уровней, в частности, определить количество повторных передач на транспортном уровне (TCP retransmissions), число пакетов с нулевым размером окна, время выполнения сетевых транзакций, величину задержки при передаче пакетов и др. Подобные данные, без всякого сомнения, являются очень хорошим показателем качества работы сети. Однако их получение и анализ связаны с рядом проблем.
Первая из них заключается в том, что для получения адекватной оценки качества работы сети необходимо собирать информацию без потерь. Другими словами, сетевые пакеты вне зависимости от степени загрузки канала связи сети при записи в буфер не должны теряться. А в случае “быстрых” сетей, например Fast Ethernet, этого можно добиться только при наличии высокопроизводительного (читай: очень дорогого) аппаратного анализатора протоколов.
Вторая проблема — сложность захвата пакетов из дуплексных каналов связи в реальном времени. Как правило, именно дуплексные каналы между коммутаторами или между коммутатором и серверами представляют наибольший интерес для анализа. С этой целью обычно используются специальные “размножители”. Их установка, как правило, сложна даже с организационной точки зрения, не говоря уже о том, что их еще надо иметь.
Но самая большая проблема — это сложность анализа информации, которая уже была получена. Чтобы сделать достоверные выводы о качестве работы транспортного и прикладного уровней сети, необходимо проанализировать тысячи захваченных пакетов. Сделать это вручную невозможно. Нужна экспертная система, которая бы на лету (в тот момент, когда информация находится в буфере) анализировала содержимое проходящих по сети пакетов. Это называется проводить “экспертный анализ трассировки на лету”. Такая функция есть только в очень немногих анализаторах сетевых протоколов.
Все перечисленные выше проблемы делают получение интегральной оценки качества сети на основе анализа сетевого трафика относительно дорогим и сложно реализуемым с организационной точки зрения процессом.
|
|
|
Диагностика каналов связи на основе интегральных показателей
Недостатки традиционных подходов заставили разработчиков диагностических средств искать новые, более эффективные подходы к диагностике сетей. В последнее время наиболее активно развивается подход, основанный на анализе интегральных показателей качества работы сети. В англоязычной литературе существует несколько терминов, так или иначе связанных с ним: управление производительностью приложений (Application Performance Management — APM), управление уровнем обслуживания (Service Level Management — SLM), соглашение об уровне обслуживания (Service Level Agreement — SLA). Соответствующие средства выпускают, например, следующие компании: Ganymede Software (Pegasus, Chariot), Lucent Technologies (Vital Suite), CompuWare (EcoSYSTEMS), BMC Software (COMMAND/POST), Platinum Technology (TransTracker, WireTap), Concord Communications (Network Health) и многие другие.
Несмотря на то что в мире этот подход развивается очень активно, в России он известен мало. Причина — в высокой стоимости соответствующих средств и, главное, в отсутствии развитого рынка услуг в области консалтинга и технического аудита сетей. Именно независимые эксперты, как правило, помогают компаниям организовать контроль за работой как сети, так и пользовательских приложений. Есть даже специальный термин для этой услуги — аутсорсинг.
Учитывая все сказанное выше, мы проиллюстрируем интегральный подход на отечественном и относительно недорогом программном продукте FTrend 1.1, который разработан компанией ProLAN специально для этих целей. Он входит в состав пакета FTest Pro.
|
|
|
Как должны работать каналы связи сети
Как мы уже говорили в начале статьи, прежде чем приступать к диагностике каналов связи с помощью любого инструментария, необходимо знать, что, собственно, мы собираемся увидеть с помощью этого средства. Другими словами, необходимо знать, как должны функционировать каналы связи сети. Иначе ее диагностика становится бессмысленным занятием. Поскольку в качестве интегрального критерия используются скоростные характеристики сети, мы должны четко представлять, какие значения скоростных характеристик можно считать нормальными в каждом конкретном случае. Учитывая ограниченные возможности журнальной статьи, мы не будем подробно останавливаться на этом вопросе. Скажем только, что с этой целью на Web-сервере компании ProLAN (
/), в его разделе “База Знаний Он-Лайн” специально созданы рубрики, которые так и называются: “Посмотри, как у других, и сравни” и “Производители Софта рекомендуют”. В этих рубриках приведены результаты тестирования различных сетей, которые можно использовать в качестве ориентиров, как должны работать их каналы связи.
|
|
|
Как реально работают каналы связи сети
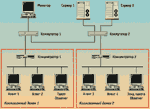
Имея эталонные данные с параметрами нормальной работы сети, интересно узнать, как каналы связи работают реально. Продемонстрируем методику оценки качества работы каналов связи на примере сети, изображенной на рис. 1.
В состав ее каналов связи входит множество компонентов, каждый из которых является потенциальным источником скрытых или явных дефектов. Кроме кабельной системы сети, дефекты могут быть обнаружены в оборудовании и специализированном ПО коммутаторов (firmware), в концентраторах, сетевых адаптерах, установленных на серверах и рабочих станциях, в сетевых драйверах. Причиной плохой работы сети в ряде случаев являются неправильные параметры настройки сетевого оборудования и операционной системы.
Прежде чем мы начнем оценивать качество работы каналов связи (измерять скоростные характеристики), необходимо произвести декомпозицию сети и выбрать характерные функциональные цепочки сетевых компонентов — так называемые тракты. При выборе последних необходимо руководствоваться простым правилом: дефект в любом компоненте канала связи обязательно должен отразиться на скоростных характеристиках хотя бы одного из трактов.
В рассматриваемом примере таковыми являются: “Коллизионный домен 1 — Сервер 1”, “Коллизионный домен 1 — Сервер 2”, “Коллизионный домен 2 — Сервер 1”, “Коллизионный домен 2 — Сервер 2”. Скоростные характеристики каждого тракта контролируются соответствующим агентом. Таким образом, в рассматриваемой сети необходимо и достаточно иметь четыре агента: Агенты 1 и 4, которые настроены на работу с Сервером 1; Агенты 2 и 3 — на работу с Сервером 2. Настроив работу агентов, можно приступать к получению интегральной оценки качества работы сети.
Еще раз хотим отметить, что дефект в любом компоненте канала связи должен отразиться на значениях измеряемых скоростных характеристик. Следствием дефекта сети могут быть низкие абсолютные значения скоростей или “провалы” в них. Измерив скоростные характеристики за длительный период времени, например за месяц, можно построить базовую линию скоростных характеристик сети.
Очевидно, что изобразить на одном графике информацию, собранную в течение месяца, или проанализировать 30 графиков, каждый из которых характеризует работу сети за целый день, весьма затруднительно. Собранную информацию нужно представить в удобной для анализа форме. Таковой будет статистическая оценка, являющаяся результатом статистической обработки полученных данных. Выполнение такой обработки данных и представление ее в графическом виде — одна из задач программы FTrend 1.х.
При статистической обработке вычисляются такие параметры скоростных характеристик сети, как минимальное, максимальное и среднее значения, среднеквадратическое отклонение от среднего значения, а также строится выборочная плотность вероятности (гистограмма). Статистическая оценка позволяет однозначно определить, какие значения с какой вероятностью принимают скоростные характеристики сети в реальном режиме ее эксплуатации. Это и является базовой линией скоростных характеристик каналов связи сети.
Иногда целесообразно предварительно отобрать данные, по которым будут формироваться статистические оценки. Например, выбрать данные, полученные только в рабочие дни и часы. Иначе информация, собранная в периоды отсутствия сетевой активности (ночь и выходные дни) может исказить объективную картину режима эксплуатации сети. В пакете FTrend 1.1 это делается автоматически с помощью специального графического инструментария.
Таким образом, результаты статистической обработки скоростных характеристик по всем трактам предстают в виде точных количественных оценок того, как реально работают каналы связи сети в течение заданного периода времени.
|
|
|
Почему каналы связи сети работают плохо
После получения объективных данных, свидетельствующих об отклонениях в работе каналов связи, очередным логическим этапом исследования сети становится установление источников неисправностей. Однако, прежде чем мы объясним, как это сделать, скажем несколько слов о причинах, которые могут оказать существенное влияние на скоростные характеристики сети. Все их разнообразие можно условно разделить на две категории. К первой относятся явные дефекты сети. Как мы говорили выше, их относительно легко увидеть с помощью средств анализа сетевого трафика (анализаторов протоколов, программ на базе SNMP). Вторую категорию составляют дефекты, которые очень сложно или вообще невозможно увидеть при анализе сетевого трафика. Это скрытые дефекты, для их локализации традиционно требуются мощные аппаратные анализаторы протоколов и экспертные системы, о чем мы уже говорили выше.
Таким образом, задача выяснения причин плохой работы каналов связи сводится к последовательному решению двух задач. Сначала необходимо узнать, являются ли причиной плохой работы сети явные дефекты, поскольку выявить это не самая сложная задача. Если же обнаружится, что явные дефекты отсутствуют, а сеть тем не менее работает плохо, то это свидетельствует о наличии в ней скрытых дефектов.
|
|
|
Первый этап: локализуем явные дефекты сети
На этом этапе необходимо выяснить, какие именно характеристики сетевого трафика в наибольшей степени влияют на скоростные параметры исследуемой сети. Это можно сделать, вычислив корреляционные зависимости между базовой линией (трендом) скоростных характеристик сети и базовыми линиями (трендами) характеристик сетевого трафика. При этом все базовые линии должны быть “привязаны” к единой временной шкале.
Базовая линия скоростных характеристик сети измеряется программой FTrend 1.х. Эта базовая линия дает нам интегральную оценку качества работы сети. Но, если мы видим, что интегральная оценка нас не устраивает, нужно определить причину отклонений. Для этого необходимо получить базовую линию характеристик сетевого трафика, которая измеряется анализаторами протоколов и программами на базе SNMP. Таким образом, для точной локализации явного дефекта одновременно с программой FTrend 1.х необходимо использовать анализатор протоколов или программу на базе SNMP. В своей практике для этих целей мы чаще всего применяем пакет Observer компании Network Instruments (см. рис. 1).
Специальная утилита Trend Analyst, входящая в состав программы FTrend 1.х, позволяет импортировать данные из внешних программ, “привязывать” их к единой временноўй шкале и вычислять корреляционные зависимости между собранными и импортированными данными. Такими внешними программами, как правило, и являются анализаторы протоколов и программы на базе SNMP. В момент написания этой статьи утилита Trend Analyst позволяла импортировать данные из программ HP Open View NNM, Observer и MS Performance Monitor.
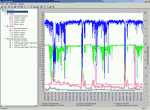
Импортированные данные записываются в базу данных FTrend 1.х. Это позволяет на одном графике (см. рис. 2) увидеть скоростные характеристики сети и импортированные данные (например, загрузку сети, сервера, и т. п.).
При этом вся отображаемая информация одинаково усреднена и “привязана” к единой временноўй шкале. Затем с помощью утилиты Trend Analyst можно вычислить корреляционные зависимости между скоростными характеристиками сети и импортированными данными.
Вычисление корреляционных зависимостей является мощным средством для локализации дефектов сети. Если скоростные характеристики сети условно назвать функциями, а характеристики сетевого трафика — аргументами, то с помощью утилиты Trend Analyst можно получить точные количественные оценки того, в какой степени каждая функция зависит от каждого конкретного аргумента или нескольких аргументов. Например, какова зависимость скорости от загрузки сети, числа ошибок передачи данных и т. п. Это позволяет достоверно и однозначно локализовать все явные дефекты сети.
Используя пакет FTrend 1.1, можно получать два типа корреляционных зависимостей: парное и множественное корреляционные отношения. Под первым из них мы будем понимать корреляционное отношение функции к одному аргументу. Например, в какой степени скорость сети зависит от загрузки порта коммутатора, а в какой — от числа ошибок передачи данных и. т. п.
Под множественным корреляционным отношением мы будем иметь в виду корреляционное отношение функции к двум и более аргументам. Хотим напомнить, что если какая-либо функция слабо коррелирует с каждым отдельно взятым аргументом из некоего списка, то это еще не означает, что она слабо коррелирует одновременно со всеми аргументами из данного списка. Этим и объясняется необходимость вычисления множественного корреляционного отношения.
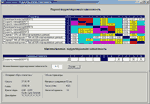
Результаты вычислений парных корреляционных отношений представляются в виде таблицы (рис. 3).
В каждой ее клетке выводится корреляционное отношение между характеристиками строки и столбца. Дополнительно величина корреляционного отношения кодируется цветом. Вычисление множественного корреляционного отношения осуществляется в режиме диалога. После выбора интересующей вас функции (характеристики) и набора аргументов по нажатию кнопки на экран выводится вычисленное значение соответствующего корреляционного отношения.
|
|
|
Второй этап: локализуем скрытые дефекты
Если на первом этапе вам удастся определить характеристики сетевого трафика, существенно влияющие на скоростные характеристики сети, считайте, что вам повезло. По крайней мере в вашей сети отсутствуют скрытые дефекты. Если же вам не удастся найти такие характеристики, то это будет означать, что в сети есть скрытые дефекты. Они могут стать, например, причиной периодической порчи индексного файла СУБД на сервере, но никаких признаков этого, кроме самого факта порчи индексного файла, вы можете и не увидеть. При наличии скрытого дефекта основная задача — локализовать его с точностью до устройства или компонента сети, после чего остается только заменить последний.
Локализация скрытых дефектов осуществляется правильным выбором трактов. Поясним это на примере. Предположим, что в сетевом адаптере Сервера 2 (см. рис. 1) имеется скрытый дефект. В этом случае скоростные характеристики трактов “Агент 2 — Сервер 2”, “Агент 3 — Сервер 2” будут подвержены влиянию этого дефекта, а скоростные характеристики трактов “Агент 1 — Сервер 1” и “Агент 4 — Сервер 1” — нет. (Скоростные характеристики трактов, в которых есть дефектный компонент, будут иметь низкие абсолютные значения или же синхронные “провалы”.) В общем случае причина может быть в Коммутаторе 2 или в Сервере 2, поскольку только эти два компонента являются общими для трактов “Агент 2 — Сервер 2”, “Агент 3 — Сервер 2”. Сравнивая скоростные характеристики всех четырех трактов, можно быстро и однозначно локализовать скрытый дефект.
|
 |
наверх
|
|