|
|
|
|
| |
 к выбору публикации к выбору публикации
|
|
|
Анализ сетевых протоколов как метод оптимизации сети
Сергей Юдицкий,
Владислав Борисенко,
Петр Адаскин |
 |
Пользователей интересует прежде всего скорость и надежность сетевых приложений. Использование анализатора протоколов позволяет выяснить причину их неудовлетворительной работы.
Мы продолжаем серию публикаций, посвященных вопросам диагностики и тестирования локальных сетей. Предыдущие статьи (см. LAN №7-8, 9, 12) касались, в первую очередь, вопросов диагностики и тестирования сети на канальном и транспортном уровнях. В данной статье мы хотим уделить внимание задачам оптимизации работы сети, в частности локализации некоторых «скрытых дефектов» в архитектуре и эксплуатируемом прикладном ПО.
Сложность локализации «скрытых дефектов» в архитектуре сети и эксплуатируемом прикладном ПО заключается в том, что единственным симптомом их наличия является медленная или неустойчивая работа в сети прикладного ПО.
|
 |
Причины медленной работы ПО
Без предварительной диагностики канального и транспортного уровней сети причину медленной работы ПО определить очень сложно. Это может быть как нехватка пропускной способности или неоптимальность архитектуры сети, так и недостатки самого ПО.
Очень часто клиенты жалуются на то, что прикладное ПО периодически работает медленно. При этом компания, которая устанавливала или разрабатывала данное ПО, считает, что причина в дефектах сети, так как «во всех остальных компаниях, где это ПО установлено, оно работает хорошо». Администратор сети в свою очередь утверждает, что все остальное эксплуатируемое ПО функционирует нормально, поэтому виновато, скорее всего, именно недавно установленное ПО.
Если вы хотите определить причины медленной работы ПО, то их выяснение целесообразно начать с проведения первичной диагностики сети. Первичная диагностика сети предполагает выполнение, как минимум, следующих работ.
1. |
Диагностика кабельной системы с помощью кабельного сканера.
|
2. |
Измерение утилизации канала связи и определения зависимости времени реакции прикладного ПО от утилизации канала связи.
|
3. |
Измерение числа коллизий и ошибок на канальном уровне.
|
4. |
Измерение доли широковещательного и группового трафика в общем трафике.
|
5. |
Определение факта повторных передач пакетов на транспортном уровне сети, т. е. факта перегрузки сервера, коммутатора и других устройств.
|
Предположим, что после проведения первичной диагностики сети явных дефектов не обнаружено. Все параметры находятся, насколько можно судить, в допустимых пределах, а прикладное ПО тем не менее продолжает работать медленно или неустойчиво. В таких случаях причину медленной работы прикладного ПО следует искать в недостатках архитектуры сети или самого прикладного ПО.
Как показывает опыт диагностики сетей, не менее чем в 50% случаев одной из причин медленной или неустойчивой работы прикладного ПО в сети оказываются недостатки его самого, но наиболее типичным случаем является совокупное влияние дефектов прикладного ПО и дефектов сети. Дефекты сети провоцируют проявление недостатков ПО. Дефекты же прикладного ПО оказываются следствием того, что программисты часто не задумываются об оптимизации своих программ для работы в сети.
Дефекты прикладного ПО могут быть очень «коварны» и проявляться спустя длительное время после ввода ПО в эксплуатацию. К этому времени исходные тексты программ могут оказаться утеряны, или компания, установившая это ПО, может прекратить свое существование. Коварство заключается еще и в том, что недостатки могут заявить о себе только в определенных сетевых конфигурациях. Например, если сеть имеет большой запас пропускной способности, то дефект не проявляется. Однако незначительное изменение архитектуры или топологии сети может стать катализатором для его проявления.
Как писал классик: «Все счастливые семьи счастливы одинаково, каждая несчастливая семья несчастлива по-своему». Недостатки прикладного ПО могут быть самыми разнообразными. В применении к локальным сетям наиболее часто встречаются три вида недостатков прикладного ПО.
- |
Дефекты ПО, приводящие к неэффективному использованию пропускной способности сети.
|
- |
Дефекты ПО, связанные с неэффективным алгоритмом блокировки доступа к общим данным в сети.
|
- |
Дефекты ПО, вызывающие неоправданные сетевые операции и, как следствие, увеличивающие время реакции прикладного ПО.
|
|
|
Неэффективное использование пропускной способности
Дефекты ПО, следствием которых является неэффективное использование пропускной способности сети, наиболее распространены. Их суть заключается в том, что функционирование программы приводит к высокой утилизации канала связи, но при этом коэффициент полезного использования сети оказывается низок (т. е. высоки накладные расходы при передаче данных). Другими словами, служебная информация составляет значительную часть всей передаваемой информации. Косвенным признаком неэффективного использования пропускной способности сети прикладным ПО может служить заметная доля коротких кадров в сетевом трафике. Мы подробно обсуждали эту проблему во второй статье нашего цикла (LAN №9).
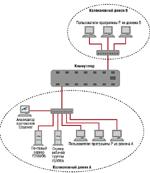
Рассмотрим пример неэффективного использования пропускной способности сети прикладным ПО, приведшего к замедлению работы пользователей других программ. Крупная коммерческая компания X обратилась к нам с просьбой выяснить причину периодического замедления работы пользователей в одном из сегментов сети - коллизионном домене А
Как выяснилось, компания X недавно провела модернизацию своей сети и установила на магистрали мощный коммутатор. Одно из подразделений компании традиционно использовало программу P для обработки информации, получаемой из удаленных офисов. Программа P работала с почтовым ящиком, расположенном на сервере Novell NetWare с именем FSNW06. Сам сервер находился в коллизионном домене A, а пользователи программы P - в доменах A и B. Получаемая с почтового сервера FSNW06 информация заносилась после обработки в базу данных на сервере рабочей группы FSNWA, находящемся в коллизионном домене A. Программа P была написана программистами компании X и использовалась в течение нескольких лет, причем никаких нареканий на ее работу не было.
После проведенной модернизации сети пользователи домена A стали жаловаться, что доступ к серверу FSNWA иногда осуществляется с большими задержками, вообще говоря, в непредсказуемые моменты времени.
Установив в коллизионном домене A анализатор протоколов Observer, мы провели первичную диагностику и выяснили следующее. Сервер FSNWA работает без перегрузки, следовательно, замедление не может происходить из-за недостаточной мощности сервера FSNWA (см. LAN №9). Число ошибок канального уровня близко к нулю, значит, замедление не может быть следствием повторных передач на транспортном уровне (см. LAN №7-8). Число широковещательных и групповых пакетов не превышает 3% от числа переданных кадров, поэтому замедление не может быть вызвано «широковещательным штормом».
Измерение степени загруженности домена A показало, что утилизация в течение рабочего дня периодически достигает 30%, однако число коллизий при этом не превышает 5% от числа переданных кадров. Как удалось выяснить, замедление происходит в моменты наибольшей утилизации канала связи (около 30%), но (и это важно!) высокая утилизация канала связи отнюдь не всегда сопровождается существенным замедлением работы пользователей домена A. Влияние утилизации канала связи на работу пользователей было проверено посредством создания с помощью генератора трафика пакетов Observer фоновой нагрузки, соответствующей уровню утилизации канала связи в 30%, и измерения времени реакции прикладного ПО на фоне этой нагрузки. Замедление работы пользователей наблюдалось, но оно было заметно меньше, чем в процессе эксплуатации сети.
Таким образом, достоверно установить причину замедления работы пользователей домена A можно было, только определив, что происходит в сети непосредственно в момент возникновения наибольших задержек. С этой целью мы настроили анализатор протоколов на циклическую запись трафика в буфер и останавливали запись в те моменты, когда наблюдалось наибольшее замедление работы пользователей. Выполнив подобную операцию несколько раз и проанализировав трафик в каждом случае, мы пришли к следующему выводу.
Наибольшее замедление работы пользователей, расположенных в домене A, происходит в те моменты времени, когда хотя бы один пользователь программы P из домена B производит обращение и/или считывание данных с почтового сервера FSNW06. Несколько меньшее замедление работы пользователей наблюдалось в те моменты времени, когда с программой P работал пользователь, расположенный в домене A.
И в том и в другом случае утилизация канала связи в домене A была близка к 30%. При этом замедление во втором случае приблизительно соответствовало задержке при создании фоновой нагрузки генератором трафика Observer.
Теоретически, на этом анализ работы сети можно было бы прекратить и рекомендовать администратору сети подключить сервер FSNW06 к выделенному порту коммутатора, но в результате остались бы невыясненными два вопроса. Почему утилизация канала связи близка к 30% при работе всего одного пользователя программы P? Почему замедление в работе пользователей домена A оказывается больше при обращении к серверу FSNW06 пользователей программы P из домена B, чем при обращении к серверу пользователя программы P из домена A, хотя утилизация канала связи в обоих случаях приблизительно одинакова?
Проанализировав трафик между пользователем программы P и почтовым сервером FSNW06, мы выяснили причину возникновения 30% утилизации канала.
Анализ трафика позволил определить следующее.
- |
Факт наличия входящего сообщения в почтовом ящике на сервере FSNW06 программа P определяет, считывая каждый раз его заголовок объемом 100 Кбайт.
|
- |
Чтение заголовка почтового ящика производится отдельными порциями данных по 1024 байт, при этом длина пакета равна 1081 байт (пакеты №№ 509-516), без использования блочной передачи данных (режим burst mode). В этом режиме заголовок почтового ящика мог бы быть прочитан всего за несколько обращений к серверу, а не за 100, как в данном случае.
|
- |
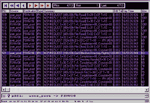
Несмотря на то что сообщения поступают в почтовый ящик с периодичностью, как правило, в несколько минут (они передаются из филиалов по модемной связи), задержка между циклами опроса почтового ящика программой не предусматривается. Пакет № 520 - окончание цикла опроса. Пакет № 521 - начало следующего цикла опроса. Как видно из Рисунка 2, задержка между этими пакетами составляет всего 0,003 секунды.
|
Ответ на вопрос о том, почему при обращении к серверу FSNW06 пользователей программы P из домена B наблюдается большее замедление в работе пользователей домена A, чем при обращении к серверу пользователя программы P из домена A, был получен путем сравнения соответствующего трафика.
Как выяснилось, магистральный коммутатор имеет следующую особенность: если в выходном буфере порта коммутатора (назовем его выходной порт) имеются данные на передачу, то при передаче данных в подключенный к порту домен сети коммутатор блокирует весь этот домен на время передачи данных. Блокировка осуществляется за счет того, что коммутатор не соблюдает паузы в 9,6 микросекунд перед передачей очередного кадра, как это предписывается стандартом CSMA/CD. Другими словами, выходной порт коммутатора ведет себя «более агрессивно», чем сетевые платы компьютеров в домене A (которые выдерживают паузу в 9,6 мкс). «Агрессивность» поведения коммутатора зависит от загруженности домена, куда подключен выходной порт. Чем выше утилизация, тем «агрессивней» ведет себя коммутатор. Строго говоря, эффект блокировки коммутатором домена сети не является дефектом коммутатора. Эта технология способствует предотвращению «заторов» в выходном буфере коммутатора (см. http://www.data.com/Lab_Tests).
Приведенный пример иллюстрирует то, как дефект прикладного ПО в сочетании со спецификой архитектуры сети может приводить к замедлению работы всех пользователей сети. Обращаем внимание читателя на то, что достоверно определить причину замедления работы пользователей домена A удалось только путем анализа пакетов сетевых протоколов.
|
|
Неэффективный алгоритм блокирования общих данных
При построении прикладного ПО на базе файловых (а не клиент-серверных) СУБД наиболее часто встречающиеся недостатки ПО являются следствием неэффективных алгоритмов блокирования общих данных разными станциями сети.
Заблокировав на длительный промежуток времени какой-то файл, одна рабочая станция может остановить работу всех остальных станций сети, также использующих данный файл для выполнения своих операций. Другими словами, для завершения своих операций все станции сети, за исключением одной, будут ждать, пока файл не будет освобожден. С этой целью они периодически будут обращаться на сервер, проверяя доступность заблокированного файла. Только после того, как файл будет освобожден, другие станции сети смогут продолжить выполнение своих операций. При этом уже другая станция может заблокировать общий файл и опять остановить работу всех остальных станций сети. Таким образом, станции сети работают фактически последовательно, а не параллельно.
Поскольку в период блокировки общего файла большинство станций не реагирует на нажатие клавиш, это создает полную иллюзию того, что причина зависания состоит в перегрузке или дефектах сети. Однако, измерив утилизацию канала связи или сервера в периоды зависания, вы можете убедиться, что утилизация этих ресурсов остается на низком уровне.
Очевидно, что при использовании файловых СУБД подобных зависаний невозможно избежать в принципе. Однако при соответствующей оптимизации алгоритма вероятность их возникновения можно свести к минимуму.
Особо мы хотели бы обратить внимание читателя на чувствительность файловых СУБД к ошибкам канального уровня сети. Если станция сети с неисправной или низкопроизводительной сетевой платой заблокирует общий файл, то, ввиду наличия проблем с доступом в сеть, она не будет освобождать его дольше, чем при использовании исправной платы.
Желающие познакомиться с этим типом недостатков ПО более подробно могут прочесть на сервере http://www.prolan.ru в разделе «Статьи и публикации» отчет компании «ПроЛАН» под названием «Некоторые особенности работы в сети прикладного ПО, реализованного с использованием файловой СУБД». Данный отчет посвящен рассмотрению результатов тестирования одного популярного программного продукта, в котором данный дефект имел место.
|
|
Неоправданные сетевые операции
Неоправданные сетевые операции - это, как правило, операции поиска информации на файловом сервере, выполняемые вследствие неэффективности алгоритма поиска, отсутствия однозначного пути к файлу или информации о типе файла. В каждом из этих случаев рабочая станция производит поиск информации во всех каталогах (подкаталогах) сервера, пока нужная информация не будет найдена. Подобный поиск создает неоправданный «паразитный» трафик в сети и увеличивает время выполнения задачи. В данной статье мы хотим привести пример для иллюстрации таких «паразитных» операций.
Администратор сети компании Y попросил нас определить причину медленной работы приложения S, время выполнения которого по сети составляло около 20 минут. Данное приложение было написано с использованием СУБД FoxPro и реализовано как набор модулей PRG для удобства внесения изменений.
Как и в приведенном выше примере, мы провели предварительную диагностику домена сети, где работает данное приложение. Никаких дефектов на канальном уровне сети, впрочем, как и перегруженности сервера, выявлено не было. После этого мы осуществили стандартную процедуру построения зависимости между временем выполнения задачи и утилизацией канала связи. Эта процедура предусматривает постепенное увеличение нагрузки в сети с помощью генератора трафика при одновременном измерении времени выполнения задачи (см. LAN №7-8). Эксперименты показали, что время выполнения задачи не зависит сколько-нибудь заметным образом от фоновой нагрузки в сети, и, следовательно, причину надо искать не в дефектах сети, а в алгоритмах работы самого прикладного ПО.
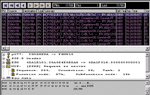
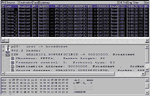
Установив анализатор протоколов Observer в домен сети, где работает данное приложение, и настроив входной фильтр для сбора пакетов на МАС-адрес станции одного из пользователей приложения S (IGOSHINA), мы записали в файл трафик, который приложение S генерировало при работе в сети. Фрагменты собранных пакетов при обмене между станцией IGOSHINA и сервером FSNW10 приведены на Рисунке 3.
Анализ трафика позволил установить причину медленной работы приложения S в сети. При запуске каждой очередной процедуры приложение S пыталось найти файл с исходным текстом модуля программы, в котором находится вызываемая процедура (в приведенном фрагменте это файл fgetdata.prg). Это делается в соответствии с алгоритмом функционирования самой СУБД FoxPro в целях проверки даты создания файла программы и наличия изменений в исходном тексте после последней компиляции. Программа ищет файл по всем известным ей каталогам, включая и каталоги на сервере. Если файл fgetdata.prg не обнаружен в одном каталоге, то поиск производится в следующем каталоге, и так до тех пор, пока файл не будет найден или не будут просмотрены все известные каталоги. Это хорошо видно в приведенных на Рисунке 3 фрагментах собранных пакетов.
-Пакет № 177. |
Станция IGOSHINA посылает серверу запрос на поиск файла fgetdata.prg (функция протокола NCP 57h, подфункция 14h). Имя файла можно видеть в нижней трети окна, где приводится содержимое пакета в шестнадцатеричном виде.
|
-Пакет № 178. |
Сервер FSNW10 отвечает, что запрашиваемый файл в текущем каталоге не найден (код завершения операции Constat=FF).
|
-Пакет № 179. |
Станция IGOSHINA посылает серверу запрос на информацию о следующем каталоге (функция протокола NCP 57h, подфункция 06h). Имя каталога можно увидеть из программы Observer при переходе на данный пакет в списке.
|
-Пакет № 180. |
Сервер FSNW10 отвечает, что запрос выполнен успешно.
|
-Пакет № 181. |
Станция IGOSHINA снова посылает серверу запрос на поиск файла fgetdata.prg.
|
-Пакет № 182. |
Сервер FSNW10 вновь отвечает, что запрашиваемый файл в текущем каталоге не найден.
|
И так до окончания процедуры поиска модуля fgetdata.prg.
В качестве решения проблемы было предложено поместить в каталог, из которого производится запуск приложения, пустые файлы с именами модулей программы с датой создания 01-01-1980. Поиск файлов (в частности, файла fgetdata.prg) был зафиксирован анализатором протоколов. Обнаружив этот файл и проверив, что дата компиляции старше, чем дата файла с исходным текстом, программа S переходит непосредственно к ее выполнению. После реализации этой рекомендации время выполнения программы S сократилось с 20 до 4 минут.
|
|
Недостатки архитектуры сети
В отличие от обрыва кабеля или выхода из строя сетевой платы недостатки архитектуры сети не столь заметны. Приведем один показательный пример.
В рамках проводимой нами кампании по экспресс-диагностике локальных сетей с использованием анализатора протоколов Observer нас пригласили «вылечить» сеть. Проблема состояла в том, что станции одного из сегментов сети 10Base2 не могли подключиться к серверу. Найти причину оказалось несложно: сетевая плата на сервере, подключенная к домену 10Base2, вышла из строя. Однако в процессе диагностики сети мы выяснили, что в этом домене сети отношение числа коллизий к числу успешно передаваемых кадров доходит до 300% при том, что утилизация домена не превышает 15%! Другими словами, только каждый четвертый кадр передается без коллизий. На наш вопрос, как сеть работала до того момента, когда сетевая плата на сервере вышла из строя, ответ был следующим: «Мы уже пять лет работаем в этой сети, и до сих пор все было нормально».
Оставим этот пример без комментариев. Напомним только фразу из монолога М. М. Жванецкого о том, что «отечественная обувь тоже хороша, если другой никогда не носили».
Кстати, в данном случае повышенное число коллизий было следствием неправильной топологии линий заземления компьютеров. Вероятнее всего, по этой же причине вышла из строя и сетевая плата на сервере.
Большинство проблем с архитектурой сетей оказываются следствием недостаточного внимания к вопросам оптимизации работы сети как системных интеграторов, так и администраторов сетей.
Часто системные интеграторы под задачей «создания сети» у клиента понимают исключительно объединение активного сетевого оборудования в единую систему таким образом, «чтобы все работало». Вопросы оптимизации архитектуры сети на этапе ее создания, как правило, не ставятся, так как системные интеграторы редко устанавливают прикладное ПО. Они считают, что это задача администратора сети.
Со своей стороны, большинство администраторов сетей под задачей «администрирования сети» понимают выполнение работ, связанных только с поддержкой пользователей сети (установка прикладного ПО, определение прав доступа пользователей к ресурсам сети, написание различных сценариев, организация сетевой печати и т. п.). При этом вопросы оптимизации работы сети остаются вне их профессиональных обязанностей. Многие из них, может быть, и хотели бы, в принципе, заняться этими вопросами, но у них либо не хватает на это времени, либо нет реального стимула. Зачем что-то оптимизировать, если и так все нормально работает (иногда как в приведенном выше примере)?
К наиболее типичным недостаткам архитектуры сети можно отнести следующие.
- |
Несбалансированность по пропускной способности различных компонентов сети, например сервера и коммутатора.
|
- |
Неоптимальный маршрут передачи сетевого трафика вследствие неправильной настройки параметров сетевой ОС или активного оборудования.
|
- |
Значительный процент широковещательных и групповых пакетов вследствие неоптимальной настройки параметров сетевой ОС или активного оборудования.
|
Вопросы несбалансированности по пропускной способности различных компонентов сети мы подробно рассмотрели во второй статье (см. LAN №9). За исключением недостаточной пропускной способности сетевых ресурсов (канала связи, коммутаторов, маршрутизаторов, сервера), все остальные недостатки архитектуры сети в той или иной степени являются следствием неправильной или неоптимальной настройки параметров активного оборудования и/или сетевой ОС.
Многих ошибок можно было бы избежать, внимательно прочитав инструкцию по эксплуатации оборудования. Однако, поскольку значительная часть активного сетевого оборудования работает по принципу Plug-n-Play, делается это далеко не всегда. Так, например, в инструкции по эксплуатации коммутатора Super Stack II Swich 1000 компании 3Com, как минимум, в двух местах написано, что режим коммутации Intelligent Flow Management нельзя использовать, если к порту коммутатора подключен концентратор. Тем не менее мы часто встречаемся с ситуациями, когда это требование не соблюдается. Сеть при этом работает плохо, но работает!
В данной статье мы хотели бы рассказать о некоторых любопытных, с нашей точки зрения, недостатках архитектуры сети, с которыми нам приходилось встречаться в процессе диагностики и тестирования сетей.
|
|
Неправильная настройка клиентов Novell NetWare
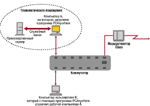
Компания Z обратилась к нам с просьбой выяснить причину неустойчивой работы в сети пользователя B, когда он связывается с удаленным компьютером A при помощи программы PCAnywhere (фрагмент схемы локальной сети компании Z приводится на Рисунке 4). Удаленный компьютер A находится в специальном помещении и подключен к производственному серверу через специальный служебный канал связи (не Ethernet). Через него пользователь B и управляет работой производственного сервера. Компьютер пользователя B и удаленный компьютер A находятся в разных доменах сети, но подключены к одному и тому же коммутатору. Неустойчивость работы проявляется в том, что в течение дня скорость работы пользователя B варьируется в широких пределах. Замедление наблюдается в непредсказуемые моменты времени.
Исследование доменов сети A и B на канальном уровне показало, что трафик в этих доменах очень низкий, а ошибки канального уровня отсутствуют. Из этого мы сделали вывод, что причину неустойчивой работы пользователя B следует искать в протоколах более высоких уровней. Это можно сделать только с использованием анализатора сетевых протоколов.
Установив анализатор протоколов Observer в том же домене сети, где находится пользователь B, мы записали в файл трафик между компьютером пользователя B и удаленным компьютером A. Фрагменты записанных пакетов приведены на Рисунке 5.
Анализ трафика показал, что компьютер пользователя B и удаленный компьютер A при работе программы PCAnywhere используют в качестве транспорта протокол IPX, но настроены на работу с разными типами кадров. В первом случае это формат кадров 802.3, что соответствует сети IPX 4DA13101. Во втором случае это формат кадров 802.2, что соответствует сети IPX 4DA12101. По этой причине маршрут обмена между станциями проходил не только между портами коммутатора (как предполагалось), но и через находящийся в сети маршрутизатор Cisco, который выполнял маршрутизацию пакетов с трансляцией протоколов в соответствующие типы кадров.
Очевидно, что подобное взаимодействие нельзя назвать эффективным. Объем сетевого трафика между компьютерами при такой их конфигурации удваивается. Скорость обмена между компьютерами зависит от загруженности как самого маршрутизатора, так и домена сети, к которому он подключен, не говоря уж о том, что пропускная способность самого маршрутизатора ниже пропускной способности коммутатора.
После настройки компьютеров на работу с одинаковыми типами кадров сети Ethernet скорость обмена между ними увеличилась и стабилизировалась.
|
|
Неправильная настройка алгоритма Spanning Tree
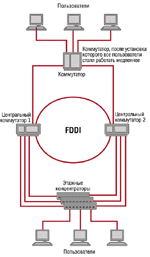
Сеть компании V, изображенная на Рисунке 6, строилась с учетом повышенных требований к отказоустойчивости. Магистраль создавалась на базе высокопроизводительных коммутаторов, связанных друг с другом сетью FDDI. В целях повышения отказоустойчивости каждый концентратор сети был подключен одновременно к двум центральным коммутаторам по 10BaseT. Серверы сети были распределены между двумя коммутаторами. При выходе из строя любого канала 10BaseT между этажным концентратором и центральным коммутатором (или слотом центрального коммутатора) сеть продолжала работать по резервному каналу.
Спустя некоторое время компания создала еще одно подразделение, деятельность которого требовала повышенной пропускной способности сети при работе с производственным сервером. Для этих целей вместо одного из концентраторов компанией был закуплен и установлен коммутатор для подключения производственного сервера по технологии Fast Ethernet и предоставления каждому пользователю данного подразделения канала на 10 Мбит/с. Вновь установленный коммутатор был подключен к центральным коммутаторам по той же схеме, что и работавший ранее концентратор.
Однако, вопреки ожиданиям пользователей, время реакции эксплуатируемого в сети прикладного ПО не уменьшилось, а увеличилось.
Гипотеза о причине проблемы была высказана практически сразу после того, как администратор сети изложил нам суть проблемы. По нашему предположению она заключалась в том, что после замены концентратора на коммутатор пути передачи данных в сети изменились в соответствии с алгоритмом Spanning Tree. Вновь установленный коммутатор был выбран в соответствии со значением своего MAC-адреса в качестве корневого коммутатора сети, и передача информации между центральными коммутаторами стала производиться не по кольцу FDDI со скоростью 100 Мбит/с, а через вновь установленный коммутатор со скоростью 10 Мбит/с. Анализ сетевого трафика в сети с помощью анализатора протоколов Observer полностью подтвердил эту гипотезу.
В соответствии с алгоритмом Spanning Tree, выбор корневого коммутатора осуществляется, исходя из комбинации постоянного параметра - MAC-адреса коммутатора и настраиваемого параметра - приоритета коммутатора. Нами было предложены два решения проблемы. Первое состояло в отключении поддержки алгоритма Spanning Tree на новом коммутаторе, а второе - в изменении значения приоритета вновь установленного коммутатора (Priority) для того, чтобы он не выбирался в качестве «корневого». Клиентом было выбрано второе решение, после чего время реакции прикладного ПО существенно снизилось.
|
|
Повышенное число широковещательных пакетов
Снижение числа широковещательных и групповых пакетов является важной задачей в больших распределенных сетях. Широковещательные пакеты предназначаются всем станциям в домене сети. В результате, при большом числе широковещательных пакетов, скорость работы всех пользователей домена сети снижается. Если число широковещательных пакетов превышает 8-10% от общего числа пакетов, то такой эффект называется «широковещательным штормом». Широковещательный шторм является следствием недостаточной продуманности архитектуры сети. Мы подробно писали об этой проблеме (см. LAN №9).
Заметим, что при проведении диагностики сети важно не только определить факт наличия в сети «широковещательного шторма», но и понять причину его возникновения. Широковещательный шторм почти всегда является следствием ошибок в настройке активного оборудования или сетевой ОС. На практике такие дефекты сложно локализовать без проведения детального анализа сетевых протоколов. Ниже мы рассмотрим несколько возможных причин широковещательного шторма на следующем примере.
В процессе обследования локальной сети компании W был выявлен значительный процент широковещательных пакетов в нескольких доменах сети. Их доля в общем трафике превышала пороговое значение 8%. Локальная сеть компании W представляет собой крупную распределенную сеть, построенную на базе сетевой ОС Novell NetWare 4.11. Большинство станций сети работает под управлением операционной системы Windows 95.
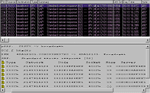
Установив в один из доменов сети анализатор протоколов Observer, мы записали в файл трафик в тот момент, когда в сети наблюдался широковещательный шторм. Анализ трафика позволил выявить несколько недостатков в архитектуре сети (см. Рисунок 7).
Каждый широковещательный пакет, переданный станцией, работающей под управлением Windows 95 (на рисунке - user), тиражировался всеми серверами в кадрах Ethernet другого формата. Кадр в формате 802.3 соответствует сети IPX 4DA13101, кадр в формате 802.2 - сети IPX 4DA12101. В результате количество широковещательных пакетов увеличилось почти на порядок. Причина такой ситуации является следствием активизации опции тиражирования пакетов NetBIOS через протокол IPX на серверах Novell NetWare.
В качестве решения этой проблемы нами было предложено удалить с тех рабочих станций, где они не нужны, клиентов для сети Microsoft и отключить на серверах Novell NetWare опцию тиражирования пакетов NetBIOS через протокол IPX. Для этого на сервере надо запустить утилиту SERVMAN и, выбрав в меню пункт «Server Parameters»->«Communication»->«IPX NetBIOS replication option», установить значение 0.
Еще один способ сокращения числа широковещательных пакетов в исследуемой сети заключался в следующем.
Для сетей Novell NetWare характерно большое число широковещательных пакетов SAP, рекламирующих различные сервисы сети. Сеть компании W территориально распределена по нескольким площадкам, причем они объединяются в единую корпоративную сеть с помощью маршрутизаторов. Очевидно, что часть рекламируемых сервисов одной площадки не представляет интереса для пользователей другой площадки. Это относится, прежде всего, к серверам печати, очередям заданий и т. п. Таким образом, большинство пакетов SAP, пересылаемых между удаленными площадками, представляют не что иное, как «паразитный» трафик. Как видно из Рисунка 8, декодированный пакет SAP содержит объявления об услугах серверов печати HP LaserJet/QUICK SILVER HEWLETT PACKARD (сервис 030Ch). Эти серверы находятся через три транзитных маршрутизатора от домена сети, где производился сбор пакетов (параметр HOPS=03). Условно говоря, маловероятно, чтобы пользователи, находящиеся в Москве, захотели печатать на принтере, установленном в Красноярске.
Использование механизма фильтрации на маршрутизаторах, связывающих между собой площадки сети компании W, позволило исключить передачу «ненужных» пакетов SAP, что привело к существенному сокращению числа широковещательных пакетов в сети. Но необходимо помнить, что перед установкой на маршрутизаторах механизма фильтрации пакетов SAP данную операцию требуется тщательно спланировать. В противном случае, пользователи могут не получить доступ к действительно нужным удаленным ресурсам корпоративной сети.
Сергей Семенович Юдицкий - генеральный директор ЗАО «ПроЛАН», Владислав Витальевич Борисенко - системный инженер ЗАО «ПроЛАН», Олег Игоревич Овчинников - эксперт ЗАО «ПроЛАН», с ними можно связаться по адресу: netproblems@testlab.ipv.rssi.ru или http://www.prolan.ru.
|
 |
наверх
|
|